이전에 텍스트 데이터를 다룬 경험이 있다면 정리되지 않은 지저분한 데이터 세트가 여러분의 업무를 얼마나 힘들게 만들 수 있는지 잘 알 것입니다. 대부분 원시 데이터가 이처럼 비구조적인 형태로 제공된다는 사실은 부정할 수 없는 진실입니다. 이 블로그에서는 RegEx(정규 표현식)의 정의, RegEx로 수행할 수 있는 작업 및 무료 RegEx 도구에 대해 알려드리겠습니다.
정규 표현식(RegEX)이란?
정규 표현식(正規表現式, 영어: regular expression, 간단히 regexp[1] 또는 regex, rational expression) 또는 정규식(正規式)은 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어입니다. 정규 표현식은 많은 텍스트 편집기와 프로그래밍 언어에서 문자열의 검색과 치환을 위해 지원하고 있으며, 특히 펄과 Tcl은 언어 자체에 강력한 정규 표현식을 구현하고 있습니다.
컴퓨터 과학의 정규 언어로부터 유래하였으나 구현체에 따라서 정규 언어보다 더 넓은 언어를 표현할 수 있는 경우도 있으며, 심지어 정규 표현식 자체의 문법도 여러 가지 존재하고 있습니다. 현재 많은 프로그래밍 언어, 텍스트 처리 프로그램, 고급 텍스트 편집기 등이 정규 표현식 기능을 제공합니다. (위키백과에서 발췌함)
어렵게 들리지만, 이 개념은 사실 이해하기 꽤 쉽습니다. 넷플릭스에서 특정 영화를 찾고 싶다면 영화 제목 또는 제목의 일부를 검색할 수 있습니다. 그런 다음 넷플릭스의 검색 엔진은 검색 상자에 입력한 제목과 일치하는 제목의 영화를 찾고 검색 키워드와 일치하는 검색 결과 목록을 보여줍니다. 마찬가지로 정규 표현식은 찾고 싶은 영화를 검색하는 데 사용한 단어와 같습니다.
기본적으로 정규 표현식은 텍스트 문자열 전체에서 요소를 일치시키거나 요소를 대체하는 데 사용할 수 있는 텍스트 패턴입니다. RegEx는 텍스트 기반 데이터를 정리하는 강력한 언어입니다.
RegEx에서 할 수 있는 일
요컨대 HTML 태그를 일치시키고 HTML 문서에서 데이터를 추출하기 위해 정규 표현식을 사용할 수 있습니다.
일반적인 RegEx 사용 사례
규칙적인 표현은 이메일, 전화번호, 우편번호 등과 같은 일반적인 텍스트 패턴을 일치시키는 데 도움이 됩니다.
정규 표현식의 강력한 점은 다양한 문자열과 매치할 수 있다는 점입니다. 물론 HTML을 구문 분석할 때 정규 표현식을 사용하면 닫힘 태그 누락, 일부 태그 불일치 등과 같은 실수가 자주 발생할 수 있습니다. 프로그래머들은 PHPQuery, Beautiful Soup, html5lib-Python 등과 같은 다른 HTML parser를 사용할 가능성이 더 높습니다. 그러나 HTML 태그를 빠르게 일치시키려면 RegEx 도구를 사용하여 HTML 문서의 패턴을 식별할 수 있습니다. 프로그래머나 웹 데이터를 추출하려는 사람은 정규 표현식 도구를 사용하면 이 도구가 어떻게 작업 효율성과 생산성을 크게 향상시킬 수 있는지 느낄 수 있을 겁니다.
일치한 HTML 태그를 찾는 정규 표현식의 몇 가지 예를 살펴보겠습니다.
- HTML 태그를 일치시키기 위한 정규 표현식:
<(.)>.?|<(.) />
<(\S?)[^>]>.?|<.*?/>
- 모든 TD 태그와 일치하는 정규 표현식:
<td\s*.*>\s*.*<\/td>
- <img src=”test.gif”/> 와 일치하는 정규식:
<[a-zA-Z]+(\s+[a-zA-Z]+\s*=\s*(“([^”])”|'([^’])’))\s/>
이러한 정규식을 사용하여 다양한 HTML 태그를 매칭할 수 있으므로 HTML 문서에서 데이터를 쉽게 추출할 수 있습니다.
또한 정규 표현식 치트 시트를 사용하여 RegEx에 대한 빠른 참조를 얻을 수 있습니다.
정확한 정규 표현식을 생성하거나 확인하는 데 도움이 되는 인기 있는 온라인 RegEx 테스트 및 디버깅 도구를 추천드리면 다음과 같습니다.
웹 데이터를 가져오는 동시에 데이터에 대하여 다시 포맷해야 하는 경우 Octoparse를 다운로드하여 무료 RegEx 도구를 사용하여 보시길 권장해 드립니다. 소프트웨어를 열고 사이드바 메뉴에서 “도구” 아이콘을 클릭하기만 하면 됩니다.
무료 RegEx 도구 – Octoparse
최고의 웹 스크래핑 도구인 Octoparse를 사용하면 RegEx를 사용하여 필드 값의 문자를 일치시키거나 교체하여 추출된 데이터를 직접 정제할 수 있습니다.
Octoparse RegEx 도구는 다양한 기준을 설정하여 정규 표현식을 자동으로 생성하는 편리한 서비스를 제공하는 내장 도구입니다. 코딩 기초가 없으시다거나 정규 표현식을 쓰는 방법에 대해 배울 여력이 없을 때 특히 RegEx 도구가 도움이 될 것입니다.
Octoparse에서는 RegEx 도구에 액세스하는 두 가지 방법이 있습니다.
방법 1: Octoparse 데이터 정제 옵션
- 사용자 정의할 데이터 필드를 선택합니다.
- “…”을 클릭하고 “데이터 정제”를 선택합니다.
- “단계 추가”를 클릭합니다.
- 정규 표현식으로 바꾸기 또는 정규 표현식과 매치하기를 선택합니다.
- “RegEx가 어려우신가요? RegEx 도구를 사용해 보세요!””를 클릭합니다.
방법 2: 홈 화면 사이드바
- 사이드바 탐색 하단에서 “Tool Box” 아이콘을 선택합니다.
- “RegEx Tool” 클릭합니다.
이제 2가지 사례로 Octoparse에서 RegEx 도구가 어떻게 작동하는지 알려드리겠습니다.
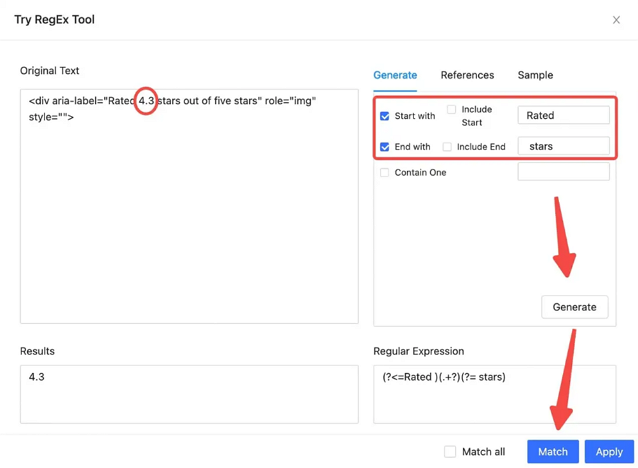
사례 1: 주변 문자 사용하여 텍스트 위치 찾기
아래 HTML에서 평점 정보를 얻고 싶다면 Octoparse의 RegEx 도구를 사용하여 주변의 “시작말” 및 “맺음말” 문자를 사용하여 요소를 일치시킬 수 있습니다.
<div aria-label=”Rated 4.3 stars out of five stars” role=”img”>
사례 2: RegEx를 작성하여 특정 정보(이메일, 웹사이트 등) 추출하기
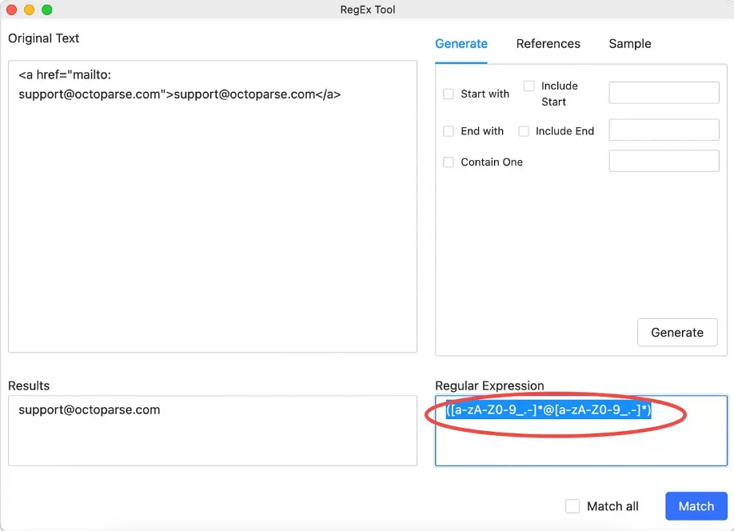
소스 코드에서 전자 메일을 추출하려면(특히 다른 구조를 공유하는 일부 URL의 경우) 아래의 RegEx를 직접 사용하여 전자 메일을 매치할 수 있습니다. RegEx 도구로 정규 표현식을 즉시 테스트하고 디버깅할 수 있습니다.
([a-zA-Z0-9_.-]@[a-zA-Z0-9_.-])