구글 시트가 웹 스크래핑을 대신해 줄 수 있다고 생각해 본 적 있나요?사실, 강력한 클라우드 기반 도구인 구글 스프레드시트는 웹사이트에서 데이터를 스크래핑할 수 있습니다. IMPORTXML 및 IMPORTHTML과 같은 강력한 기능을 통해 사용자는 웹사이트에서 직접 데이터를 추출하여 데이터 수집 및 분석 작업을 간소화할 수 있습니다. 스크래핑된 데이터는 팀이나 친구와 직접 공유하거나 다른 타사 도구와 통합할 수 있습니다.
이 블로그에서는 Google 시트를 사용한 간단한 웹 스크래핑 프로세스와 다양한 웹사이트에서 데이터를 수집하기 위해 사용하는 강력한 기능을 소개해드리겠습니다.
Google 시트를 사용한 웹 스크래핑 소개
Google 스프레드시트는 초보자와 전문가 모두에게 웹사이트에서 데이터를 스크래핑할 수 있는 쉽고 간편한 방법을 제공합니다. 특정 데이터만 가져오든, 테이블과 목록을 수집하든, Google 스프레드시트는 복잡한 코드를 작성하지 않고도 프로세스를 자동화할 수 있는 기본 도구를 제공합니다.
Google 시트에서 웹 스크래핑에 사용되는 주요 기능은 IMPORTXML과 IMPORTHTML입니다 . 두 기능 모두 URL과 관련 데이터 요소(예: XPath 또는 HTML 테이블)를 지정하여 웹사이트에서 데이터를 가져올 수 있습니다.
다음 부분에서는 이러한 기능을 사용하여 데이터를 스크래핑하는 방법을 안내하고 이를 통해 데이터 추출 프로세스를 어떻게 간소화할 수 있는지 설명합니다.
웹 스크래핑을 위한 구글 시트의 5가지 방법
방법 1: ImportXML 사용
ImportXML은 XPath 쿼리를 사용하여 XML, HTML, CSV, TSV, RSS 피드와 같은 구조화된 소스에서 데이터를 가져올 수 있는 Google 스프레드시트의 기능입니다.
사용 방법은 다음과 같습니다:
- URL: 웹페이지의 URL입니다.
- xpath_query: 원하는 데이터를 선택하기 위한 XPath 쿼리입니다.
- locale: 데이터 구문 분석에 사용할 언어 및 지역 로컬 코드입니다. 따로 지정하지 않으면 디폴트로 문서 로컬이 사용됩니다.
이렇게 하려면 먼저 새 스프레드시트를 만들거나 기존 스프레드시트를 열어야 합니다. 그런 다음 가져온 데이터를 표시할 셀을 클릭하고 추출할 요소의 URL과 XPath를 입력합니다.
웹사이트에서 대상 요소를 검사(마우스 우클릭)하여 기사 제목의 Xpath를 얻어야 합니다.
여기,
- URL: https://www.octoparse.kr/blog
- XPath 쿼리 : //h2
//h2는 Octoparse 블로그의 첫 페이지에 있는 모든 블로그 제목의 정확한 Xpath를 의미합니다.
따라서 완전한 함수는 다음과 같습니다.
가져온 데이터를 표시할 셀에 함수를 입력하세요. Google 스프레드시트가 외부에서 데이터를 가져올 수 있도록 허용하려면 ‘데이터 액세스’를 클릭해야 할 수도 있습니다.
몇 초간 로딩한 후, 블로그 1페이지의 모든 제목이 표시됩니다.
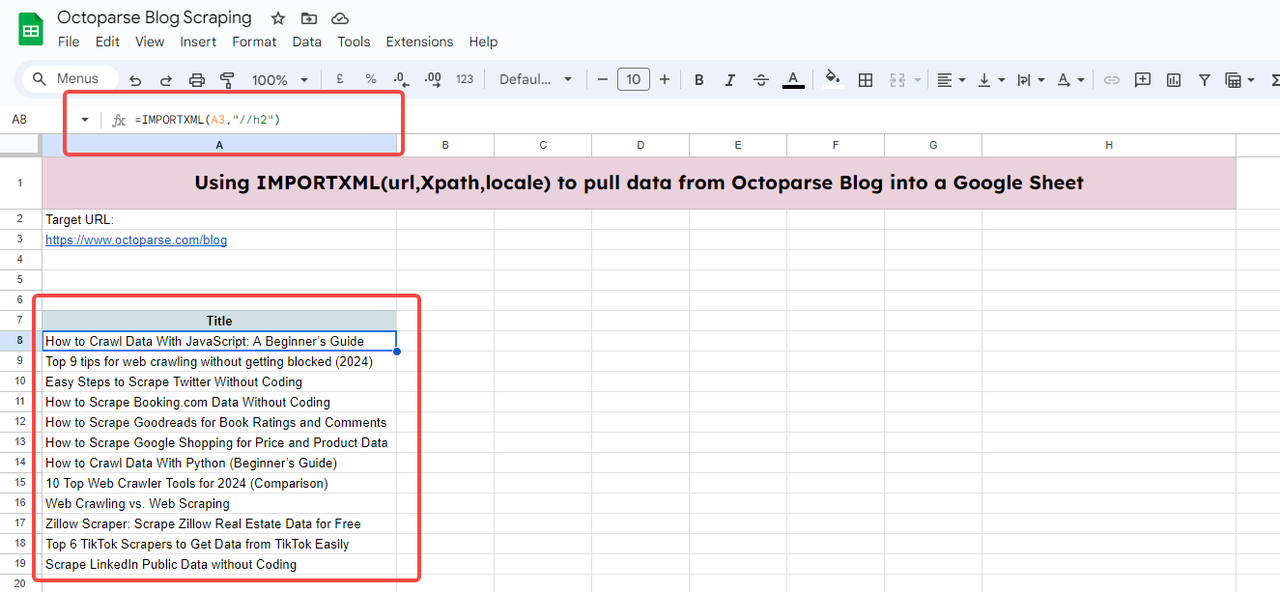
1. URL을 셀에 입력하는 경우 URL을 셀로 대체할 수도 있습니다. A3을 참조하세요.
2. Xpath와 URL을 입력할 때 따옴표를 반드시 추가해야 합니다. 셀 내용으로 대체하는 경우에는 따옴표가 필요하지 않습니다.
3. 이미 따옴표가 있는 경우 Xpath 안의 따옴표는 작은 따옴표로 묶어야 합니다. 예: “//div[@class=’author’]/span”. “//div[@class=”author”]/span”과 같이 철자가 틀리면 오류가 발생합니다.
4. 문서 로캘을 사용하려면 “Locale”을 무시해도 됩니다.XPath에 익숙하지 않은 경우 XPath 치트 시트를 참조하세요.
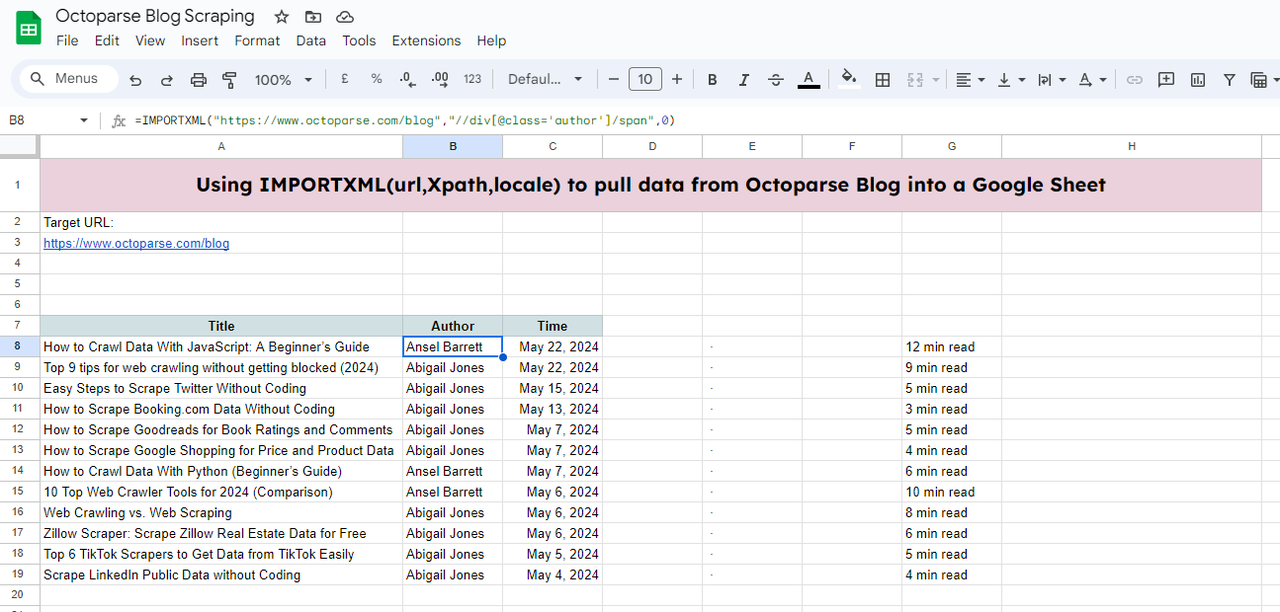
위의 동일한 단계를 따라가면 다른 데이터로 시트를 계속 채울 수 있습니다.
Google 시트 예시: https://docs.google.com/spreadsheets/d/18Tkp6rP9p1Az_AlXyOJlrqVxwESpTDOf7MSIweZnOD0/edit#gid=0
방법 2: ImportHTML 사용
Google 스프레드시트의 IMPORTHTML 함수 는 HTML 페이지 내의 테이블과 목록에서 데이터를 가져오도록 설계되었습니다. 이 함수를 사용하려면 대상 웹사이트의 URL과 “table” 또는 “list” 쿼리가 필요합니다.
함수는 다음과 같습니다:
- url: 데이터가 포함된 웹페이지의 URL입니다.
- query: 추출하려는 내용에 따라 “테이블” 또는 “목록”을 사용합니다.
- index: 웹 페이지에서 표나 목록의 위치(1부터 시작).
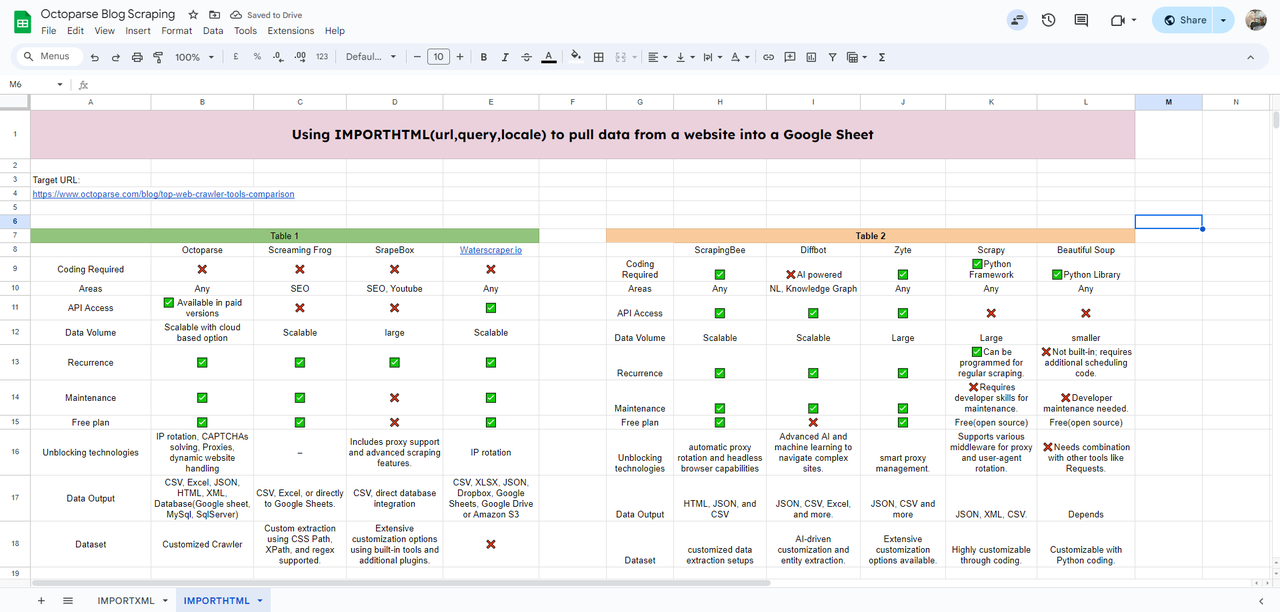
이 예에서는 Octoparse의 블로그 중 하나에서 표를 스크래핑하겠습니다.
먼저, 새로운 시트를 만든 다음 대상 URL을 엽니다.
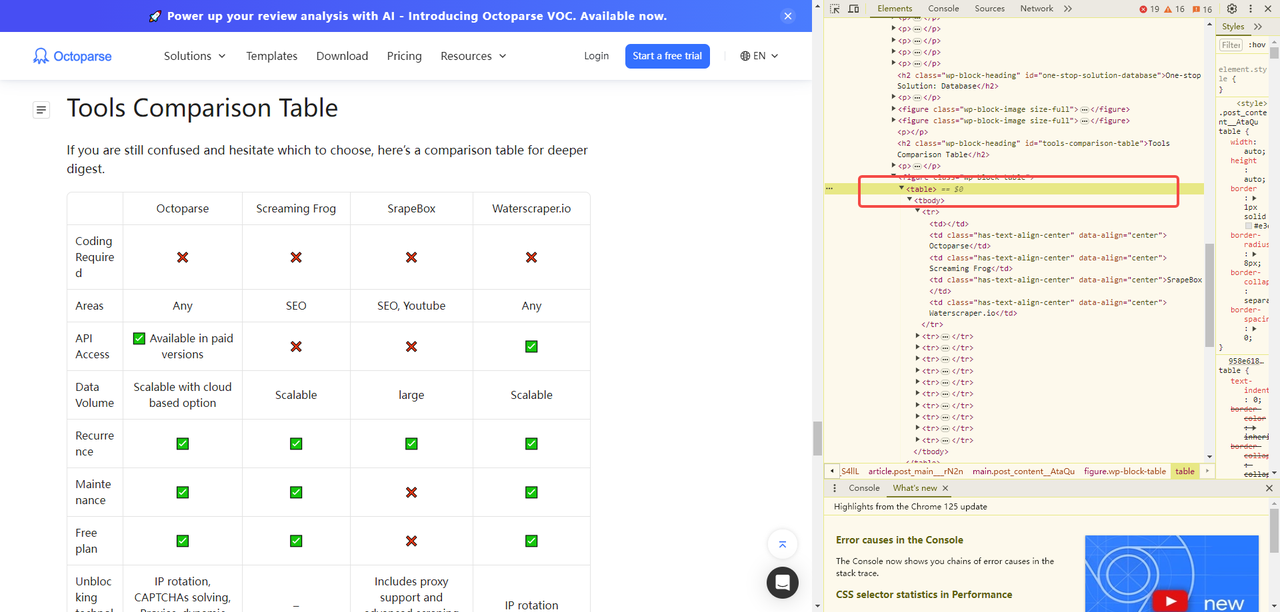
여기서 대상 테이블이 <table>이라는 라벨이 붙은 HTML을 볼 수 있습니다. 목록을 스크래핑하고 싶다면 라벨은 <list>가 됩니다.
블로그에서 표를 스크래핑하려면 가져온 데이터를 표시할 셀에 IMPORTHTML 함수를 입력해야 합니다.
입력 예시:
그러면 테이블에 로드가 완료됩니다.
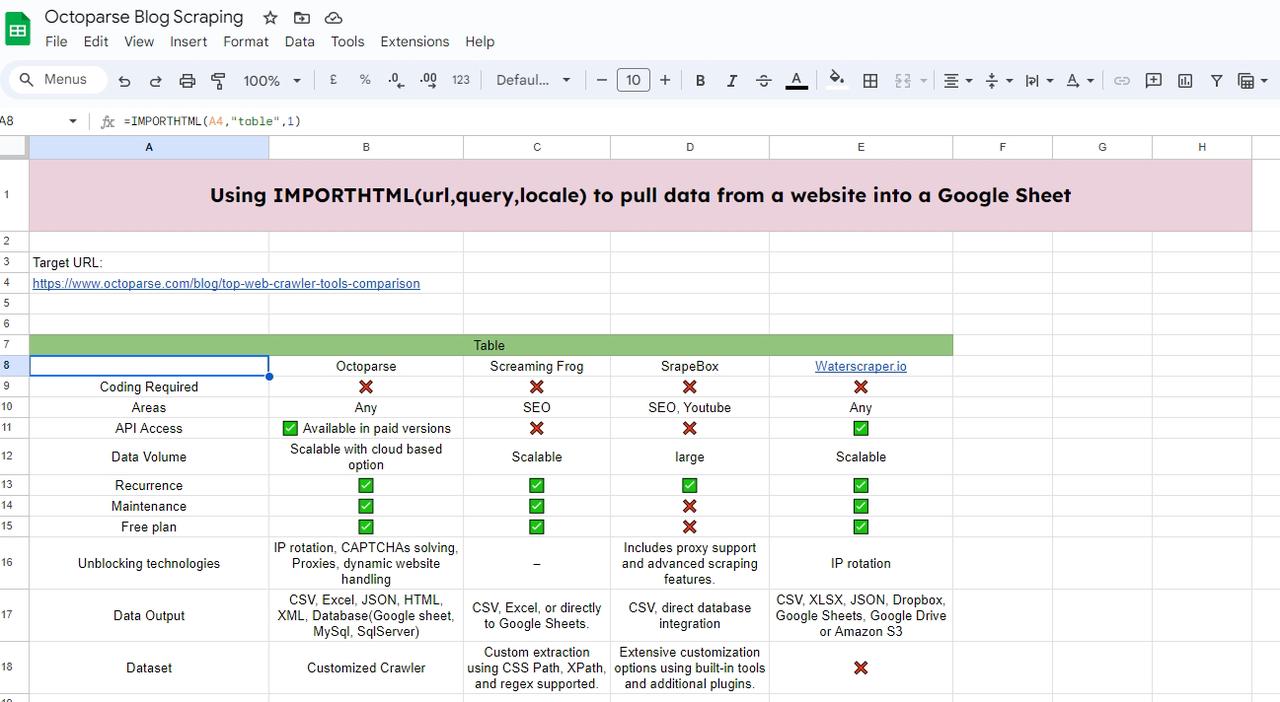
테이블 인덱스를 2로 변경하여 스크래핑을 계속하면 블로그에서 두 번째 테이블을 얻을 수 있습니다.
팁:
1. 쿼리에 큰따옴표를 추가해야 합니다.2. URL을 입력한 셀로 URL을 대체할 수 있습니다.
방법 3: ImportDATA 사용
IMPORTDATA 함수는 지정된 URL에서 CSV(쉼표로 구분된 값) 또는 TSV(탭으로 구분된 값) 형식의 데이터를 Google 시트로 직접 가져옵니다.
대상 웹사이트 URL 하나만 있으면 됩니다. 간단하죠?
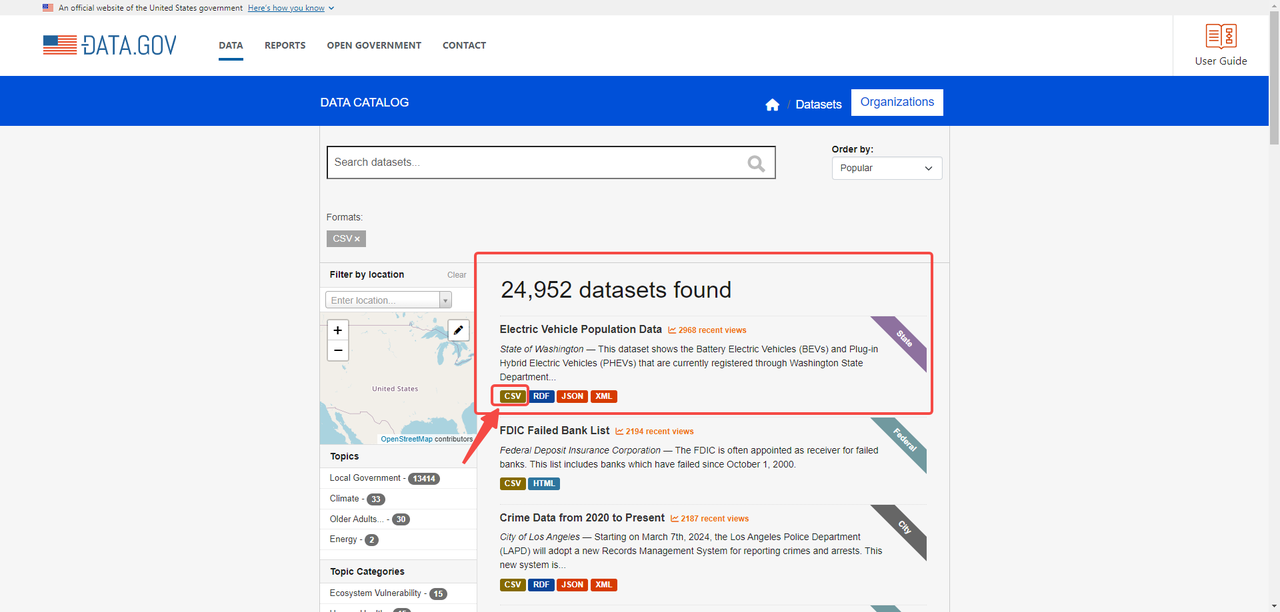
다음 웹사이트에서 데이터를 스크래핑해야 한다고 가정해 보겠습니다: https://catalog.data.gov/dataset/?res_format=CSV
웹사이트에서 다음 링크를 통해 CSV 파일을 볼 수 있습니다: https://data.wa.gov/api/views/f6w7-q2d2/rows.csv?accessType=DOWNLOAD (CSV 버튼에 마우스를 올려놓고 마우스 우클릭하면 주소가 복사됩니다)
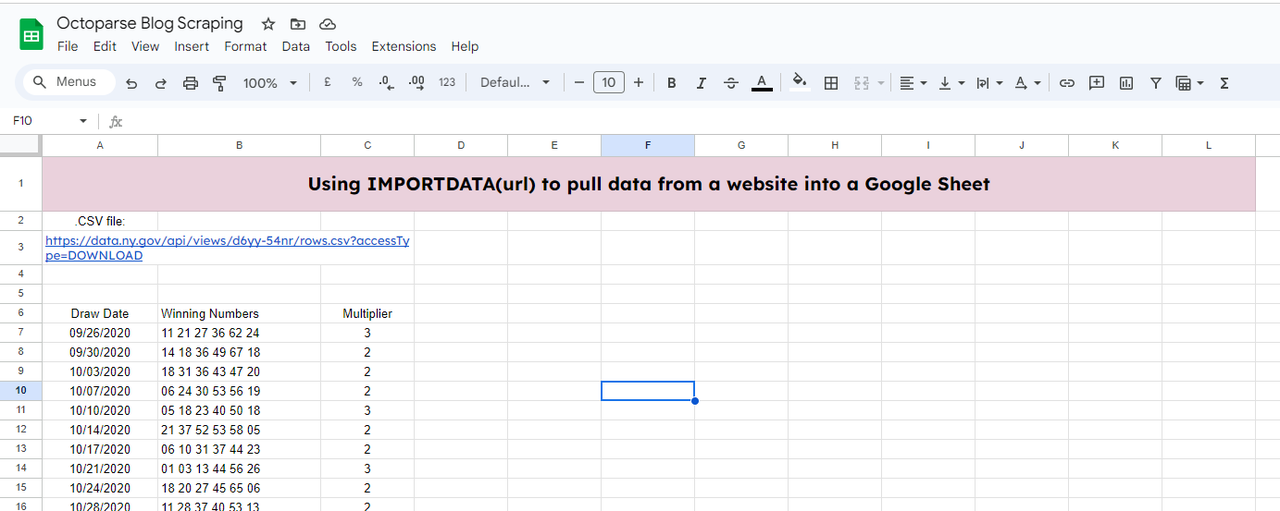
Google 스프레드시트로 데이터를 가져오려면 먼저 앞의 두 가지 방법처럼 새 시트를 만들어야 합니다. 그리고 아래 함수를 사용합니다.
=IMPORTDATA(A3,”,””)
A3: .csv 파일 링크가 있는 위치입니다.
“,”: 가져온 파일의 데이터 필드를 구분합니다.
그러면 가져온 데이터를 받게 됩니다.
방법 4: ImportFeed 사용
IMPORTFEED함수는 주어진 URL에서 RSS 또는 ATOM 피드 데이터를 가져옵니다.
이는 다음과 같습니다.
=IMPORTFEED(url, [query], [headers], [num_items])
- url: RSS 또는 ATOM 피드의 URL입니다.
- query: [선택 사항] 특정 항목을 가져오는 쿼리입니다. 기본값은
""(빈 문자열)이며, 모든 항목을 가져옵니다. - headers: [선택 사항] 헤더를 포함할지 여부입니다. 기본값은 TRUE입니다.
- num_items: [선택 사항] 가져올 항목 수입니다. 기본값은 20입니다.
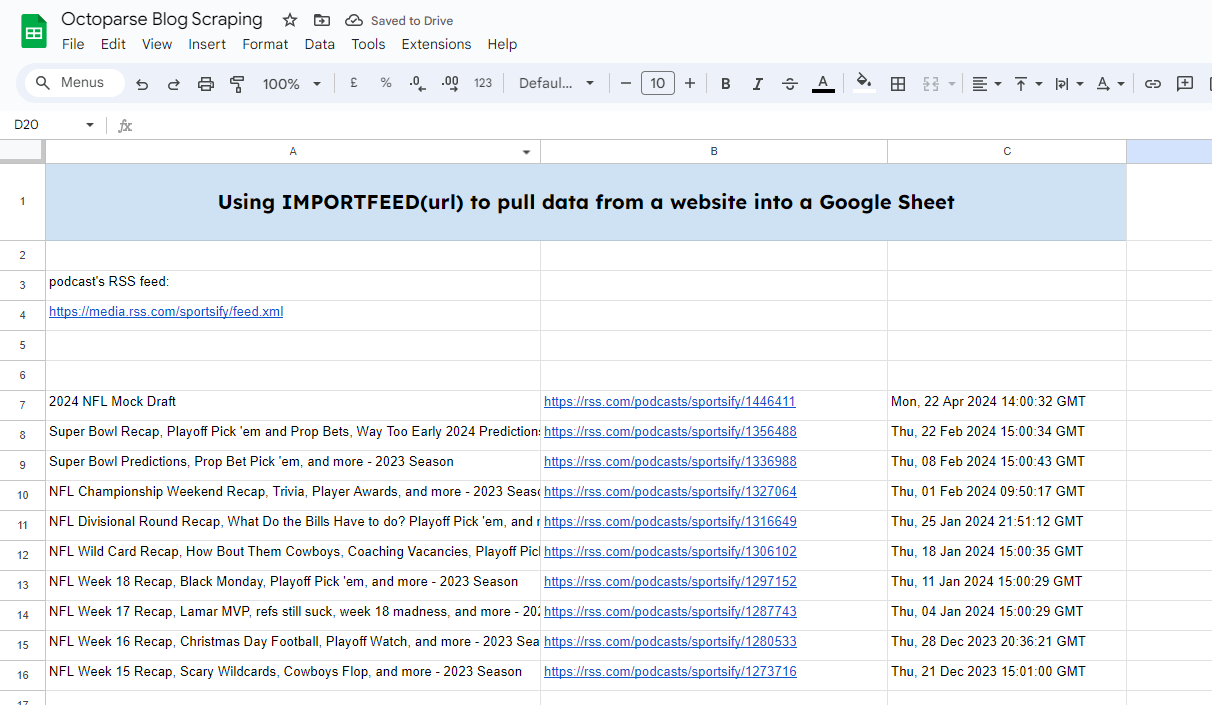
이를 위해서는 팟캐스트의 RSS 피드가 필요합니다: https://rss.com/podcasts/sportsify/
그런 다음 함수를 입력하세요.
=IMPORTFEED(A4,”,”,”,”,10)
여기에 A4 용지에 RSS 피드 링크를 입력했습니다. 그리고 10개의 피드를 추출하고 싶습니다.
그리고 당신은 정말 빨리 결과를 얻을 수 있을 것입니다.
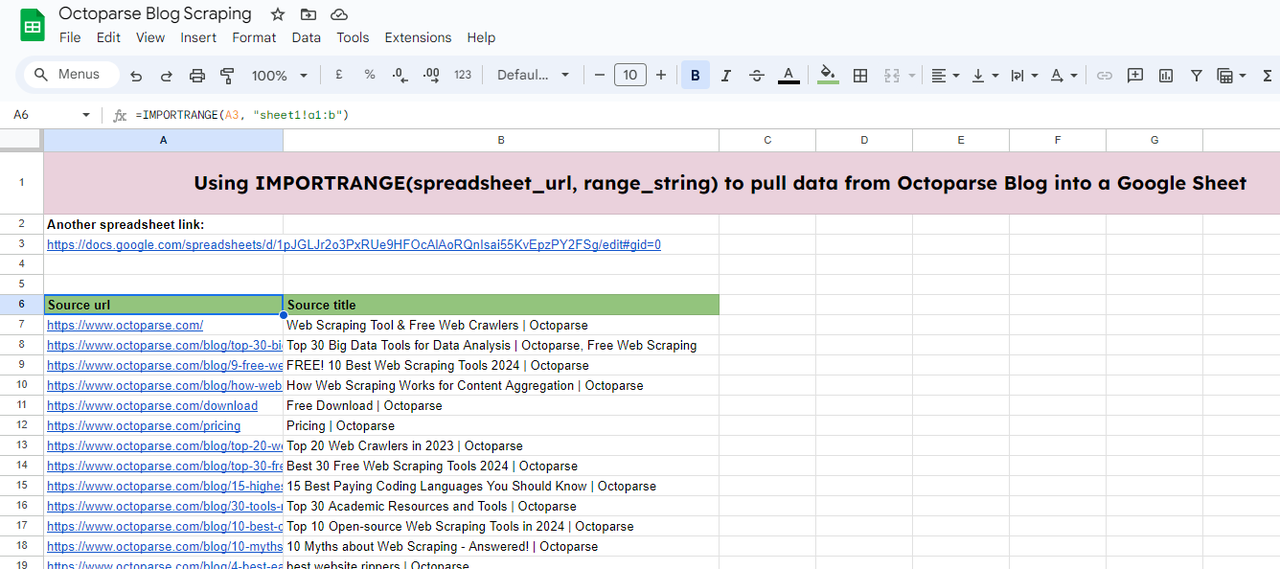
방법 5: ImportRange 사용
Google 스프레드시트의 IMPORTRANGE함수를 사용하면 한 Google 스프레드시트의 데이터를 다른 스프레드시트로 가져올 수 있습니다. 이 기능은 여러 소스의 데이터를 통합하거나 여러 시트에서 동적으로 연결하여 데이터를 공유하는 데 특히 유용합니다.
그 모습은 다음과 같습니다.
=IMPORTRANGE(spreadsheet_url, range_string)
- spreadsheet_url: 데이터를 가져올 스프레드시트의 URL입니다. 따옴표로 묶어야 합니다.
- range_string: 가져올 셀 범위를 지정하는 문자열입니다. 일반적으로
"SheetName!A1:D10".
이 예에서는 다른 스프레드시트(https://docs.google.com/spreadsheets/d/1pJGLJr2o3PxRUe9HFOcAlAoRQnIsai55KvEpzPY2FSg/edit#gid=0)에서 편집 중인 스프레드시트로 데이터를 가져와야 합니다.
이렇게 하려면 다음 함수를 입력하세요.
=IMPORTRANGE(A3, “sheet1!a1:b”)
- A3: 소스 데이터가 저장되는 곳입니다.
- sheet1!a1:b: 대상 시트의 sheet1에 있는 데이터가 필요합니다. 데이터 범위는 A1부터 B열까지입니다.
그러면 로딩이 완료된 후 데이터를 가져올 수 있습니다.
웹 스크래핑에서 Google 시트의 한계
이러한 5가지 기능을 사용하면 웹사이트에서 Google 시트로 데이터를 가져오는 방식이 간소화되지만 많은 제한 사항이 있습니다.
데이터 볼륨
이러한 함수는 페이지네이션이 포함된 대용량 데이터를 가져올 수 없습니다. IMPORTXML 예제에서 볼 수 있듯이, 한 페이지의 데이터만 스크래핑할 수 있습니다. 모든 페이지가 필요한 경우 URL을 지속적으로 변경해야 합니다.
동적 콘텐츠
위에 언급된 함수들은 정적 데이터와 정형 데이터만 스크래핑할 수 있습니다. 반면, Javascript와 AJAX로 로드된 동적 데이터는 스크래핑할 수 없습니다.
요청 횟수 제한
데이터를 너무 자주 요청하면 Google의 속도 제한이 작동하여 일시적으로 더 이상 데이터를 추출할 수 없게 될 수 있습니다.
지속적인 유지 관리
일부 기능은 데이터를 찾기 위해 웹사이트의 HTML에 의존하므로, 웹사이트의 구조가 변경되면 데이터가 영향을 받아 무효화됩니다.
대안: 코딩 없이 데이터 스크래핑
테이블이나 데이터 목록 그 이상이 필요하고 스크립트 작성이 번거롭다면 Octoparse와 같은 노코드 웹 스크래핑 소프트웨어가 최적의 솔루션이 될 수 있습니다. Octoparse는 데이터 필드를 자동으로 인식하는 자동 감지 기능을 제공하며, 고급 기능을 통해 더욱 세밀한 맞춤 설정을 지원합니다.

웹 사이트 데이터를 바로 구조화된 엑셀, CSV, Google Sheets, 데이터베이스로 내보낼 수 있습니다.
자동 인식 기능으로 코딩 없이 간단하게 데이터를 스크래핑할 수 있습니다.
수백 개의 국내외 인기 웹 사이트 스크래핑 템플릿으로 간단하게 데이터를 추출할 수 있습니다.
IP 프록시와 고급 API 기능으로 어떤 웹 사이트나 막힘없이 스크래핑할 수 있습니다.
당신이 원하면 언제든 클라우드 서비스로 데이터 스크래핑을 예약할 수 있습니다.
Octoparse는 Amazon, eBay, Google Maps, LinkedIn 등 인기 웹사이트를 위한 사전 설정된 데이터 스크래핑 템플릿도 제공합니다. 데이터 샘플을 미리 보고 몇 번의 매개변수와 클릭만으로 스크래핑을 시작할 수 있습니다. 아래 Google Maps 온라인 스크래핑 템플릿을 사용해 보세요.
https://www.octoparse.kr/template/google-maps-contact-scraper
Octoparse 사용자 정의 스크래핑을 통해 얻을 수 있는 다른 기능:
- 맞춤형 스크래퍼 서비스 및 데이터 서비스.
- 차단 방지 설정: CAPTCHA, IP 회전, 사용자 에이전트, 간격 및 로그인.
- 복잡한 사이트 처리: 무한 스크롤, 드롭다운, 호버, 재시도, AJAX 로딩.
- 클라우드 추출 및 데이터 저장.
- 무료 플랜, 유료 플랜 무료 체험 기회, 스탠다드/프로패셔널 플랜, 엔터프라이즈 플랜 제공.
- 사용량에 따라 요금을 지불하는 주거용 프록시; 155개국에서 9,900만 개 이상의 IP.
- 매우 빠른 대응을 제공하는 지원팀: intercom의 라이브 채팅을 통해 실시간 지원.
- Octoparse RPA를 통한 타사 앱 통합, API 접근.
웹사이트 데이터 스크래핑에 대해 궁금한 점이 있으시면 Octoparse 도움말 센터를 참조하세요 . 프로젝트에 적합한 데이터 서비스를 찾고 계신다면 Octoparse 데이터 서비스가 좋은 선택입니다. 저희는 고객님의 데이터 요구 사항을 정확히 파악하고 원하는 결과를 제공하기 위해 고객과 긴밀히 협력합니다.
마무리
Google 스프레드시트는 초보자도 복잡한 프로그래밍 기술 없이 기본적인 웹 스크래핑 작업을 쉽고 효과적으로 수행할 수 있는 방법을 제공합니다. IMPORTXML 및 IMPORTHTML 함수를 사용하면 웹사이트에서 구조화된 데이터를 빠르게 추출하여 스프레드시트로 가져와 분석할 수 있습니다.이러한 기능은 소규모 스크래핑에 적합하지만, 더 복잡한 작업의 경우 효율성과 정확성을 보장하기 위해 Octoparse 와 같은 고급 도구가 필요할 수 있습니다.제품 가격, 시장 동향 또는 기타 유용한 데이터를 스크래핑하는 경우 Google 시트는 간단한 웹 스크래핑을 위한 좋은 시작점을 제공합니다.



