올리브영 소개
올리브영은 대한민국을 대표하는 헬스&뷰티 전문 리테일러로 ‘더 나은 아름다움을 위한 발견의 즐거움’이라는 슬로건 아래 화장품, 생활용품, 건강기능식품 등 다양한 제품을 판매하고 있습니다. 올리브영의 가장 큰 특징은 국내외 다양한 브랜드를 한곳에서 만날 수 있는 원스톱 쇼핑 플랫폼이라는 점입니다. 글로벌 럭셔리 브랜드부터 국내 브랜드, 그리고 자체 개발한 PB(Private Brand) 제품까지 폭넓은 제품 포트폴리오를 보유하고 있어 소비자들의 다양한 니즈를 충족시키고 있습니다.
올리브영은 현재 국내 뷰티 리테일 시장에서 압도적인 1위 자리를 굳건히 지키고 있습니다. 전국에 1,300여 개의 오프라인 매장을 운영하며, 온라인과 모바일 앱을 통한 옴니채널 서비스를 제공하여 국내 최대 규모의 뷰티 전문 유통망을 구축했습니다. 올리브영 앱은 국내 뷰티 앱 중 다운로드 수와 사용률에서 독보적인 1위를 기록하고 있으며, 연간 거래액 기준으로도 국내 뷰티 이커머스 시장을 선도하고 있습니다.
이런 점때문에 뷰티 업계 종사자 또는 소매 도매 종사자일 경우 올리브영의 카테고리별 제품 랭킹을 주목하는 것이 빠르게 변하는 소비 트렌드를 읽을때 아주 유용합니다.
오늘은 무료 웹 스크래핑 도구 옥토파스(Octoparse)를 이용하여 단 2분 만에 간단한 올리브영 랭킹 탑100 상품 정보를 가져오는 방법에 대해 알려드리겠습니다.
올리브영 상품 데이터를 추출하는 방법
Step1:옥토파스(Octoparse) 다운로드 및 설치
옥토파스를 사용하려면 먼저 다운로드와 회원가입을 완료하셔야 합니다.

웹 사이트 데이터를 바로 구조화된 엑셀, CSV, Google Sheets, 데이터베이스로 내보낼 수 있습니다.
자동 인식 기능으로 코딩 없이 간단하게 데이터를 스크래핑할 수 있습니다.
수백 개의 국내외 인기 웹 사이트 스크래핑 템플릿으로 간단하게 데이터를 추출할 수 있습니다.
IP 프록시와 고급 API 기능으로 어떤 웹 사이트나 막힘없이 스크래핑할 수 있습니다.
당신이 원하면 언제든 클라우드 서비스로 데이터 스크래핑을 예약할 수 있습니다.
Step2:로그인 후 올리브영 랭킹 웹 페이지 URL 입력
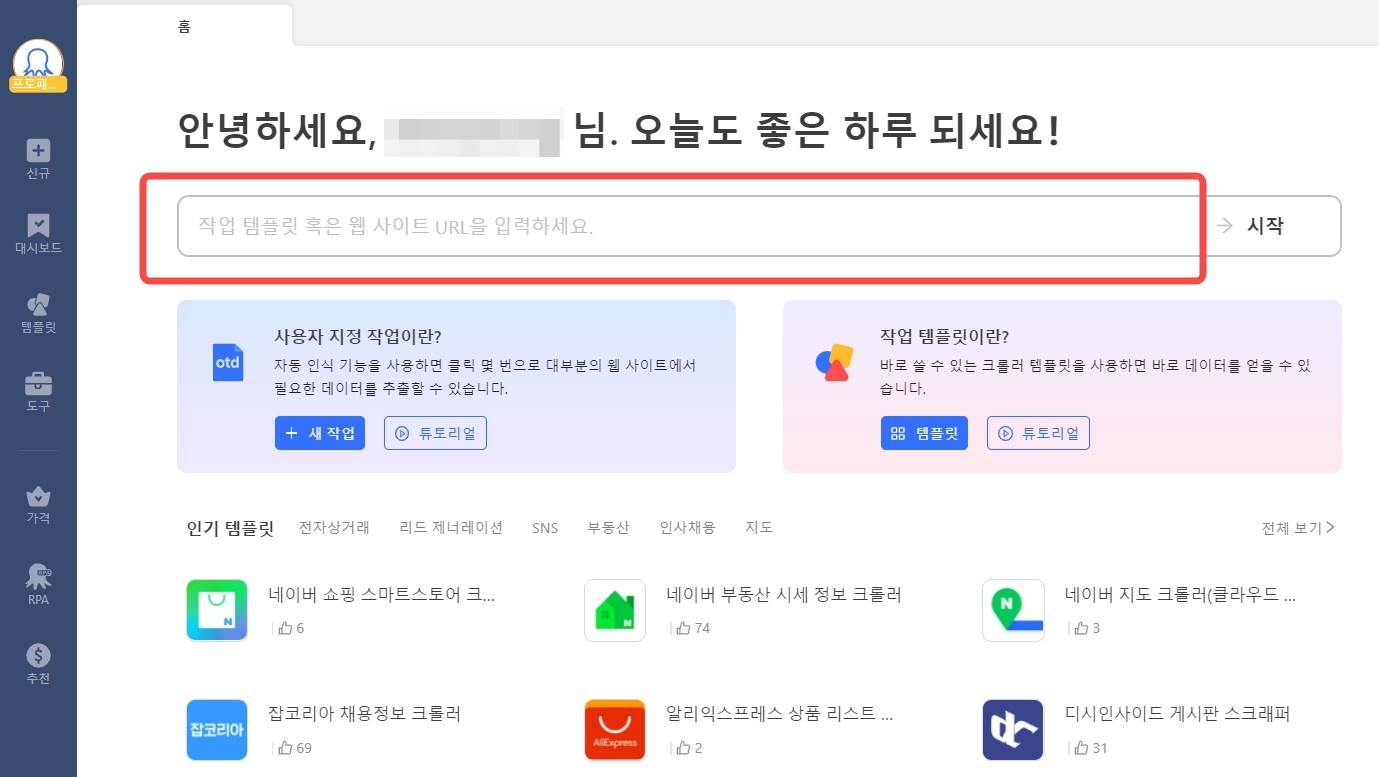
Octoparse 로그인 후 홈 화면 입력창에 추출할 상품 데이터가 있는 올리브영 랭킹 페이지 URL을 입력하고 시작 버튼을 클릭합니다.
Step3:자동 인식 시작&워크플로우 제작
시작 버튼을 클릭하고 잠시 기다리면 Octoparse 내장 브라우저에서 입력한 웹 페이지가 자동으로 로딩됩니다.
이때 팁 패널의 웹 페이지 데이터 자동 인식을 클릭하면 Octoparse가 자동으로 해당 페이지에서 추출할 데이터를 스캔하고 예상 결과를 출력합니다.
진도가 100%가 될때까지 기다립니다.
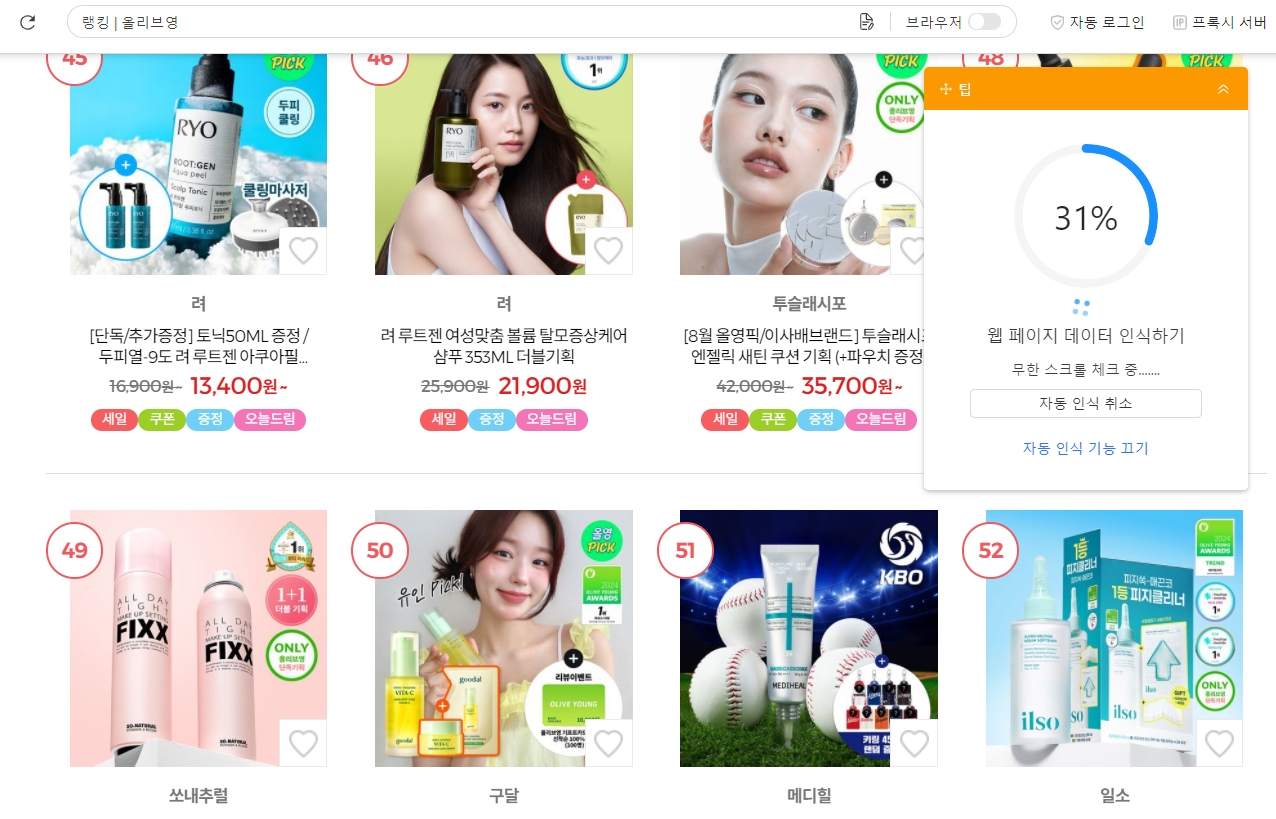
데이터 필드 자동 인식이 끝나면 올리브영 랭킹 페이지에서 추출 예상 데이터가 다음처람 연두색으로 하이라이트 표시됩니다.
먼저 워크롤로우 생성하기를 클릭합니다. 워크플로우 생성 후 추가로 추출할 데이터 필드를 추출하거나 삭제 또는 편집할수 있습니다.
Step4: 추출할 데이터 필드 설정 및 데이터 추출 작업 실행
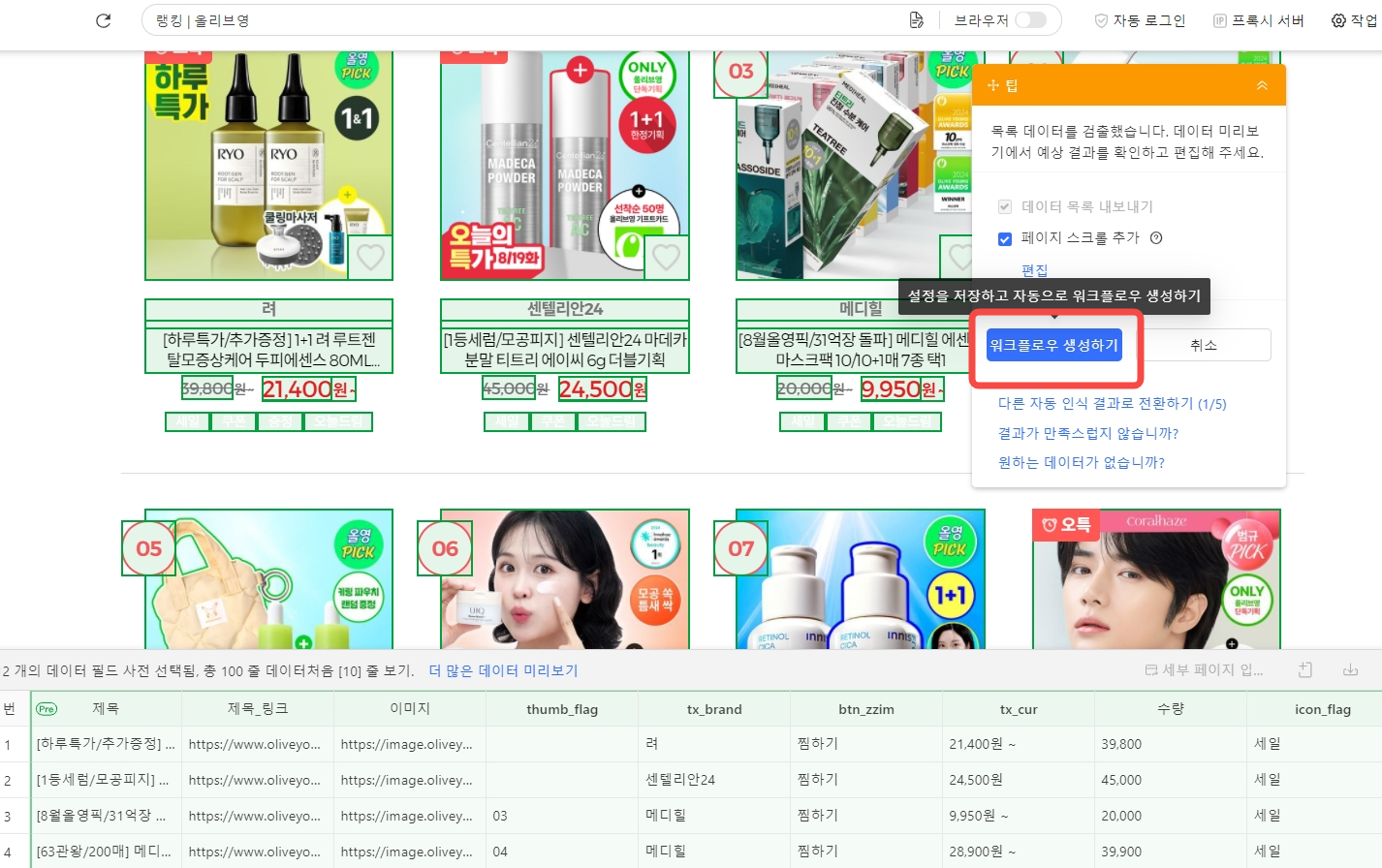
왼쪽 하단의 데이터 미리보기 섹터에서 데이터 필드를 하나 하나 확인할 수 있습니다.
데이터 필드 삭제, 추가는 물론 일부 데이터 필드에 대해 간단한 편집 작업(엑셀과 비슷)도 진행할 수 있습니다.
중복 데이터가 많은 경우 중복 제거 기능을 사용하여 처음부터 중복되지 않은 데이터만 엑셀 또는 데이터베이스로 내보낼 수 있어 후기 데이터 정제 작업량을 효과적으로 줄일 수 있습니다.
또한 필요에 따라 페이지 레벨 데이터 또는 추출 당시 시간을 추가하여 추출한 데이터를 효과적으로 관리할 수 있습니다.
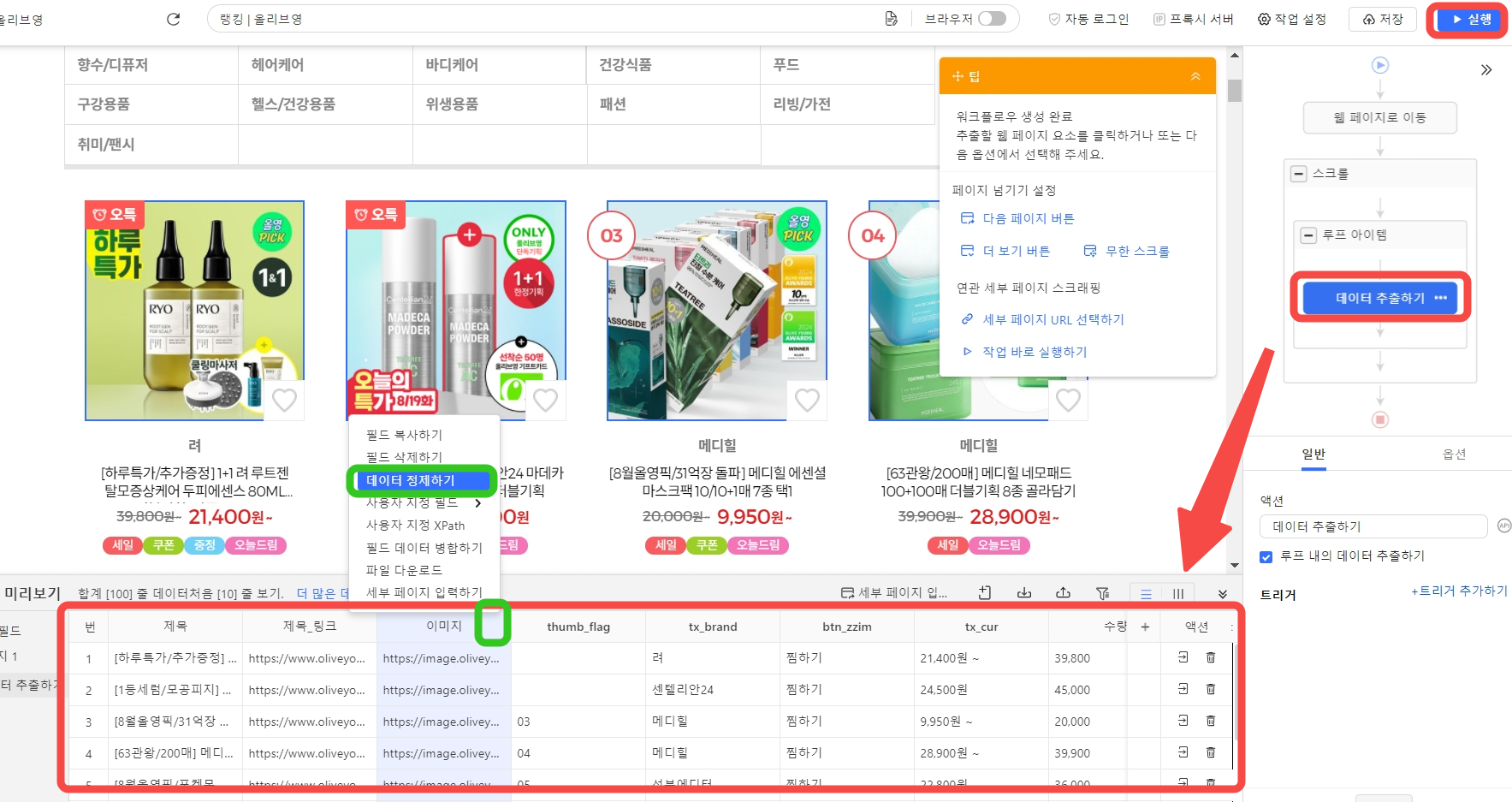
데이터 필드 확인 후 문제가 없다면 오른 쪽 상단의 실행 버튼을 클릭하여 데이터 추출 작업을 시작합니다.
실행 버튼 클릭 후 원하는 실행 모드를 선택해 주시면 됩니다.
로컬 모드(왼쪽)와 클라우드 모드(오른쪽)의 차이점은 로컬 모드는 사용 중인 디바이스를 사용하여 데이터를 추출하지만 클라우드 모드는 클라우드 노드를 사용하여 작업이 실행되기 때문에 로컬 모드보다 더 빠르고 오프라인 상태에서도 데이터 추출이 가능하다는 점입니다.
IP 주소로 볼때 로컬 모드는 현지 웹사이트 추출 시 좀 더 안정적인 장점이 있지만 외국 웹 사이트거나 이미 차단된 웹사이트 또는 밤낮없이 웹 크롤링을 해야 하는 경우는 클라우드 모드를 추천드립니다.
최근 업데이트된 8.8 버전의 경우 로컬 모드에 백그라운드 모드와 독립 브라우저 모드가 추가되었습니다. 이 두 모드는 웹 스크래핑을 좀 더 안정적으로 만들기 위해 개발된 모드로 모두 특정 크롬 브라우저를 사용합니다.
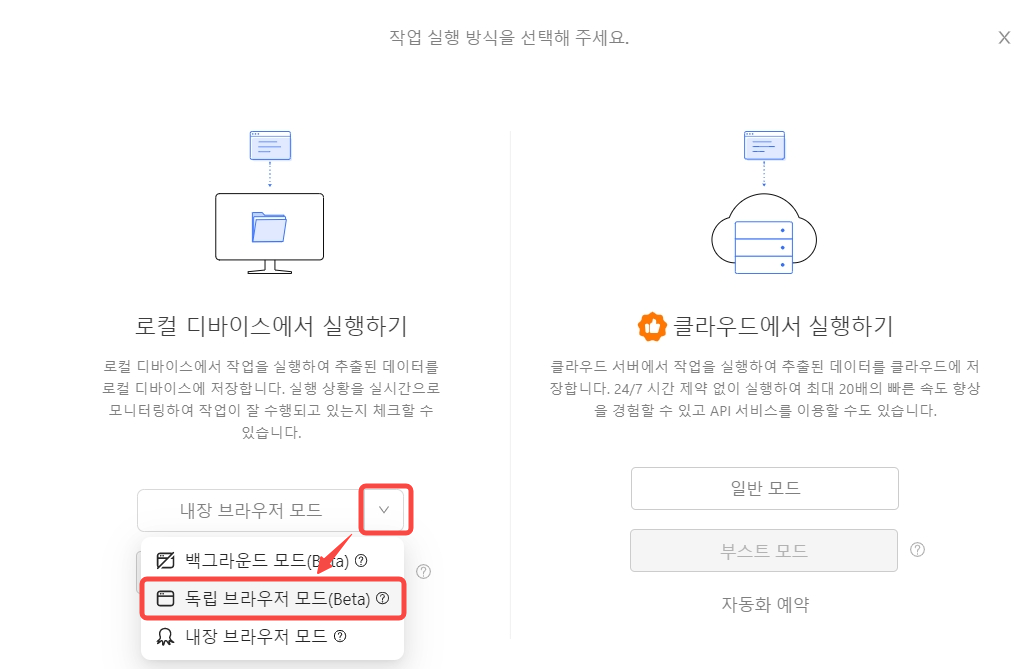
백그라운드 모드는 말 그래로 백그라운드에서 유령처럼 데이터 추출이 진행되어 사용자가 추출중인 웹 페이지를 볼 수 없습니다.
독립 브라우저 모드는 사실 볼 수 있는 크롬 브라우저에서 데이터 추출이 실시간으로 추출됩니다. 데이터 추출이 시작된 후 자동으로 튀어나오는 해당 크롬 브라우저에서는 다른 작업을 진행하면 안 됩니다. 마찬가지로 작업이 끝나면 해당 크롬 브라우저도 자동으로 꺼집니다.
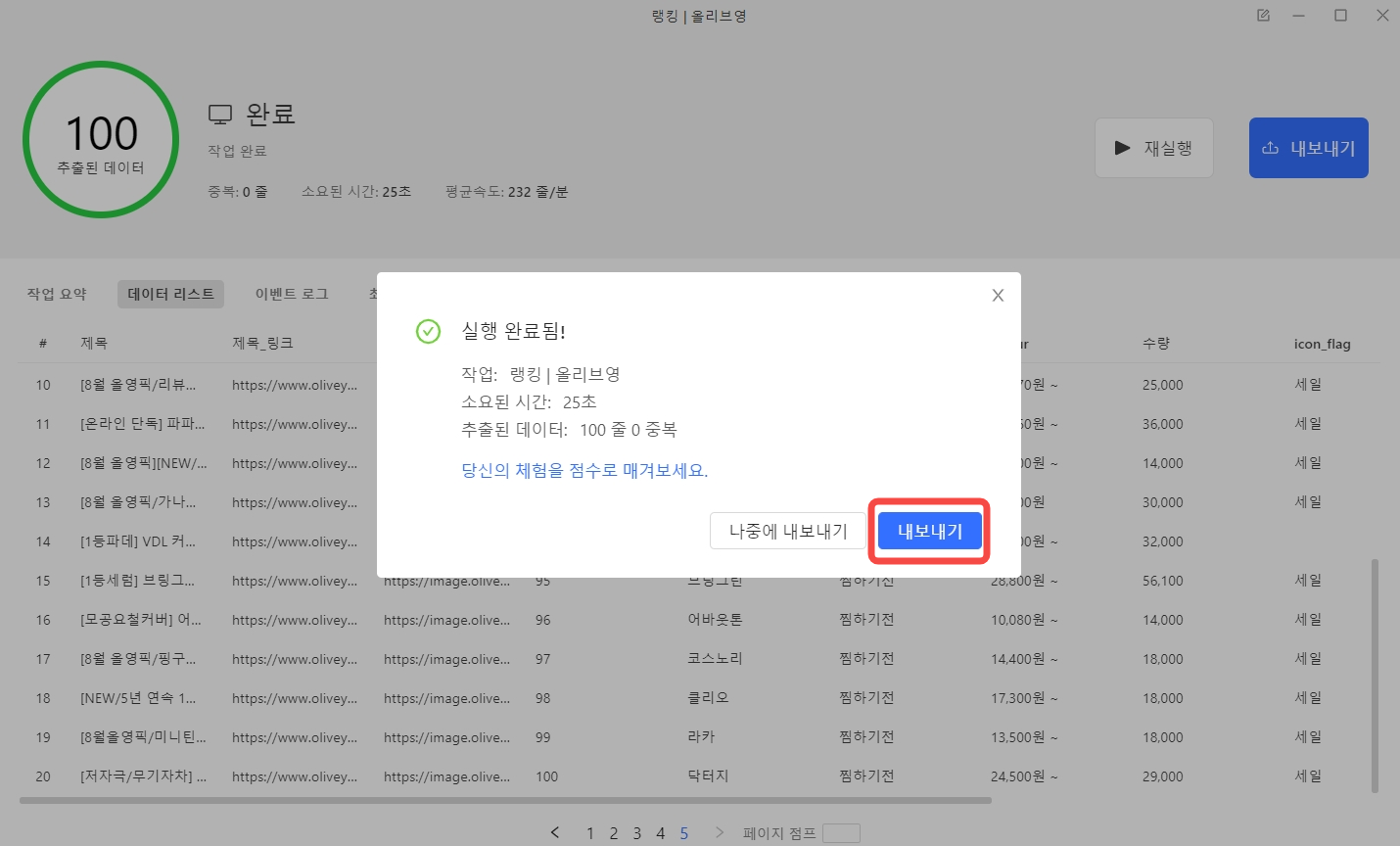
작업 실행이 완료되면 내보내기 버튼을 클릭하여 원하는 형식으로 데이터를 내보낼 수 있습니다.
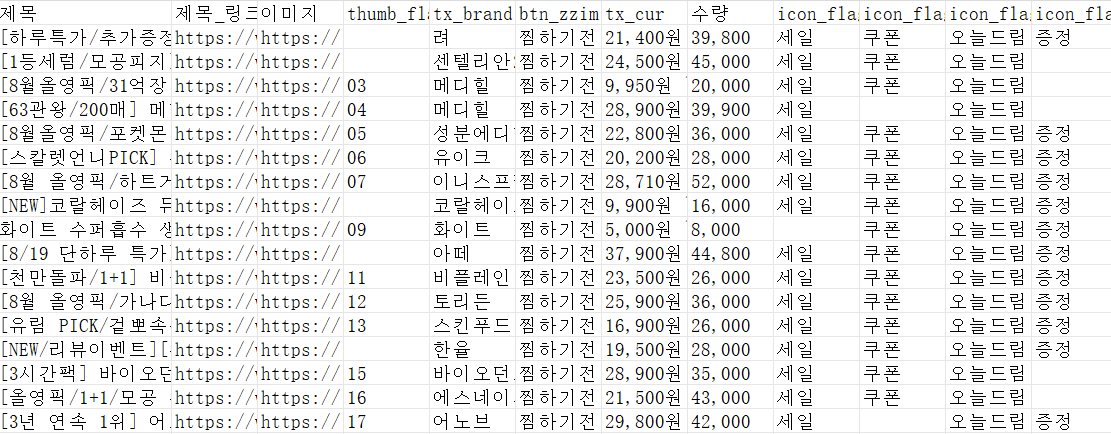
저는 간단하게 엑셀로 내보냈는데요. 결과물은 다음과 같습니다.
4번째 열에서 일부 숫자가 없는건 추출한 웹 사이트에 원래 숫자가 없는 것으로 확인되었습니다.
긴 글 읽어주셔서 감사합니다.
다음에도 유용한 웹 스크래핑 실전으로 찾아뵙겠습니다.



