온라인 서점의 방대한 도서 데이터를 활용하여 시장 분석, 개인 도서 추천 시스템 구축, 또는 단순한 데이터베이스를 만들고 싶은 분들이 많으실 텐데요. 수많은 책들의 제목, 저자, 가격, 평점 등의 정보를 일일이 수집하는 것은 결코 쉬운 일이 아닙니다.
하지만 코딩 지식이 전혀 없어도 누구나 쉽게 사용할 수 있는 강력한 웹 스크래핑 도구, 옥토파스(Octoparse)만 있다면 이야기는 달라집니다. 클릭 몇 번만으로 원하는 웹사이트의 데이터를 자동으로 수집하고, 깔끔하게 정리된 형태로 추출할 수 있습니다.
이번 포스팅에서는 국내 대표 온라인 서점인 교보문고 웹사이트를 예시로, 옥토파스를 활용해 도서 정보 리스트를 추출하는 방법을 단계별로 자세히 알려드리겠습니다. 교보문고의 베스트셀러, 신간 도서 등 원하는 모든 데이터를 손쉽게 확보하는 방법을 지금 바로 확인해 보세요!
온라인 도서 리스트를 빠르게 스크래핑하는 방법
Step1:옥토파스(Octoparse) 다운로드 및 설치
옥토파스는 직관적인 인터페이스와 다양한 기능을 통해 웹 스크래핑 작업을 단순화시켜 줍니다. 복잡한 코딩 없이, 클릭 몇 번만으로 원하는 쇼핑몰의 상품명, 가격, 이미지 URL, 상세 설명 등 모든 정보를 손쉽게 추출할 수 있습니다. 수십, 수백 개의 상품 페이지를 일일이 방문할 필요 없이, 옥토파스가 자동으로 웹을 탐색하고 데이터를 구조화된 형태로 정리해 줍니다. 엑셀, CSV, JSON 등 다양한 형식으로 추출된 데이터를 즉시 다운로드하여 분석에 활용할 수 있습니다.
옥토파스를 사용하려면 먼저 다운로드와 회원가입을 완료하셔야 합니다.

웹 사이트 데이터를 바로 구조화된 엑셀, CSV, Google Sheets, 데이터베이스로 내보낼 수 있습니다.
자동 인식 기능으로 코딩 없이 간단하게 데이터를 스크래핑할 수 있습니다.
수백 개의 국내외 인기 웹 사이트 스크래핑 템플릿으로 간단하게 데이터를 추출할 수 있습니다.
IP 프록시와 고급 API 기능으로 어떤 웹 사이트나 막힘없이 스크래핑할 수 있습니다.
당신이 원하면 언제든 클라우드 서비스로 데이터 스크래핑을 예약할 수 있습니다.
Step2:로그인 후 웹 페이지 URL 입력
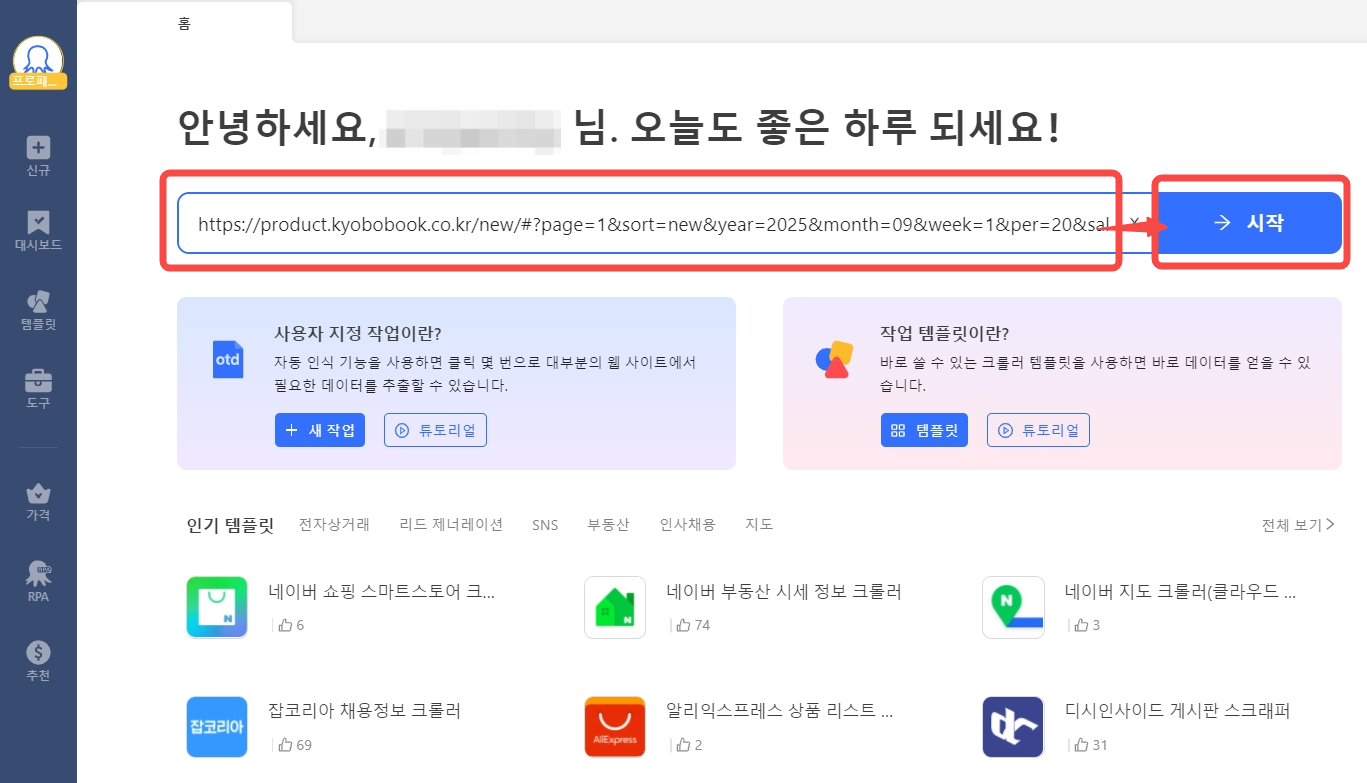
Octoparse 로그인 후 홈 화면 입력창에 추출할 상품 데이터가 있는 웹 페이지 URL을 입력하고 시작 버튼을 클릭합니다.
예시 URL: 교보문고 국내도서 신간 – 교보문고
Step3:자동 인식 시작&워크플로우 제작
시작 버튼을 클릭하고 잠시 기다리면 Octoparse 내장 브라우저에서 입력한 웹 페이지가 자동으로 로딩됩니다.
이때 팁 패널의 웹 페이지 데이터 자동 인식을 클릭하면 Octoparse가 자동으로 해당 페이지에서 추출할 데이터를 스캔하고 예상 결과를 출력합니다.
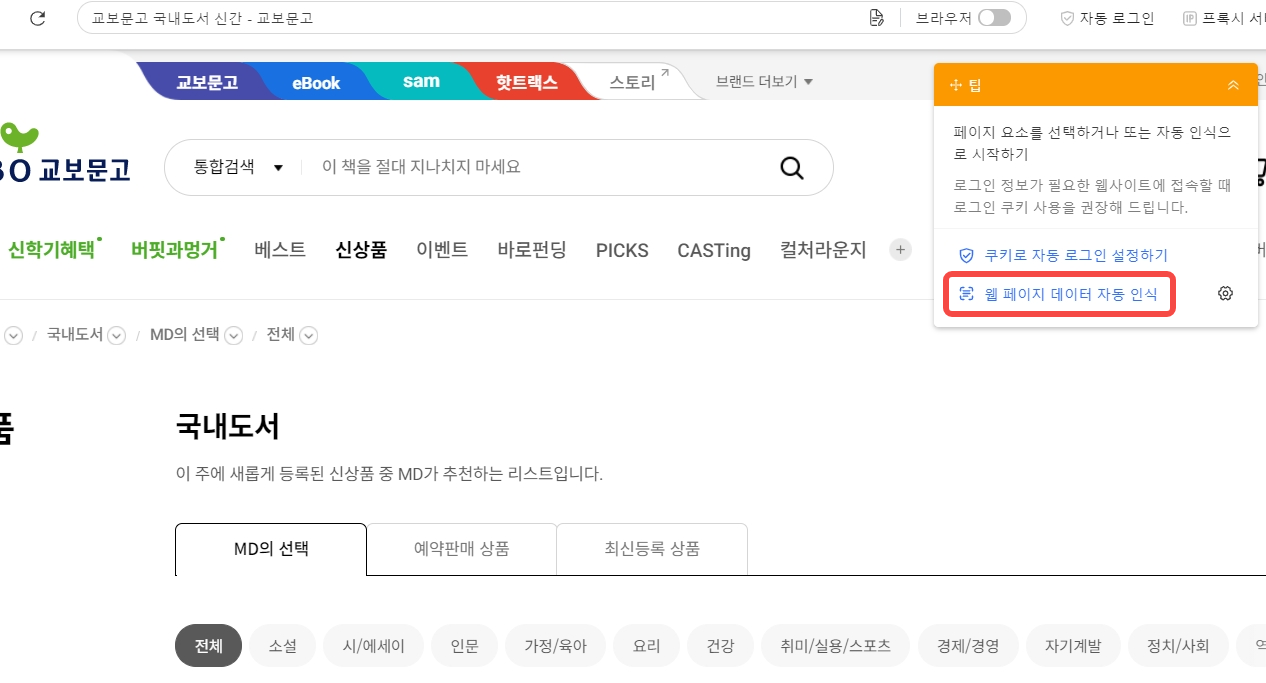
자동 인식이 100% 완료될 때까지 기다립니다.
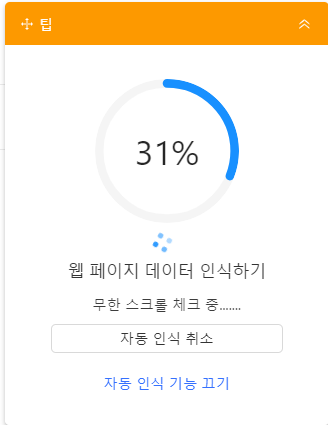
데이터 필드 자동 인식이 끝나면 교보문고 웹 페이지에서 추출 예상 데이터가 다음처럼 연두색으로 하이라이트 표시됩니다.
먼저 워크플로우 생성하기를 클릭합니다. 워크플로우 생성 후 추가로 추출할 데이터 필드를 추출하거나 삭제 또는 편집할수 있습니다.
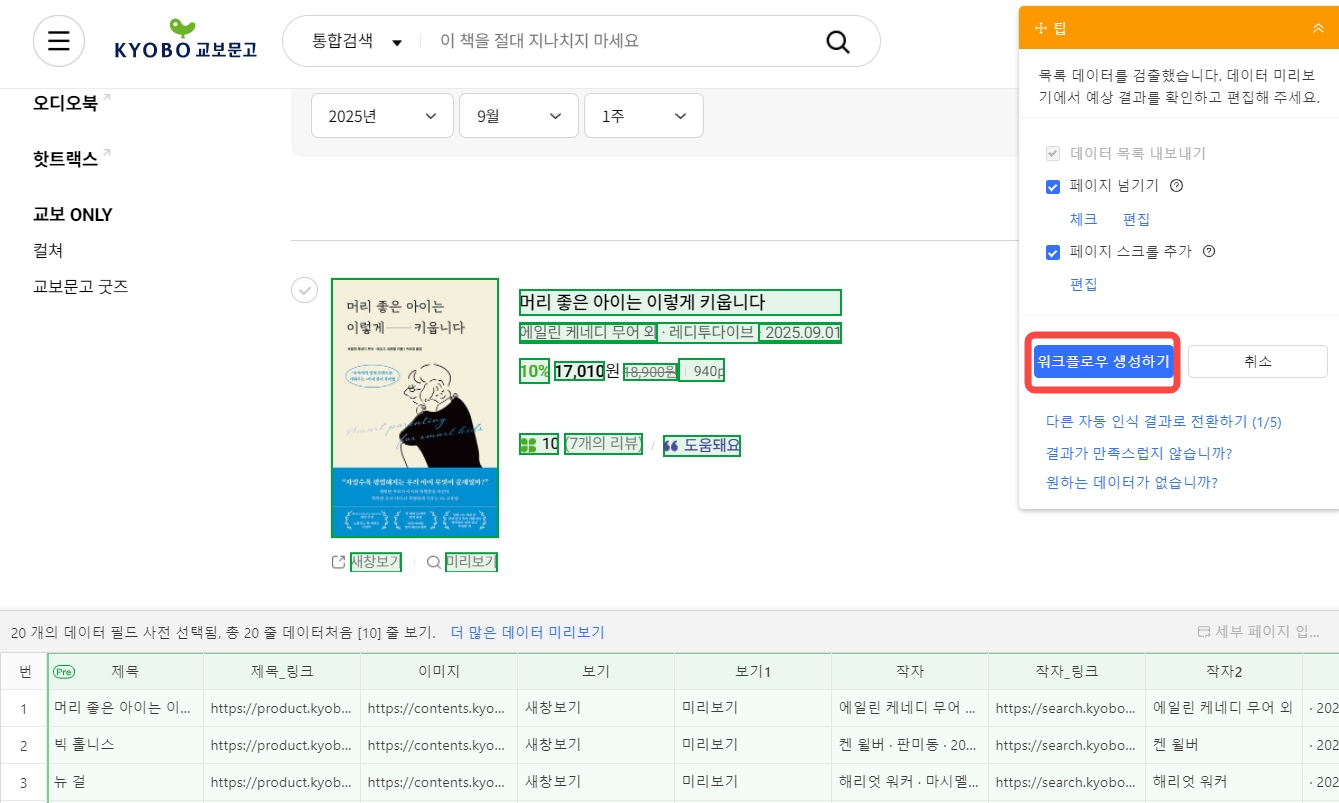
우측의 워크플로우 패널을 보시면 페이지 넘기기를 클릭했을 때 웹 페이지에서 정확하게 다음 페이지 버튼을 인식하였기에 추가로 페이지 넘기기 설정을 해주지 않으셔도 됩니다.
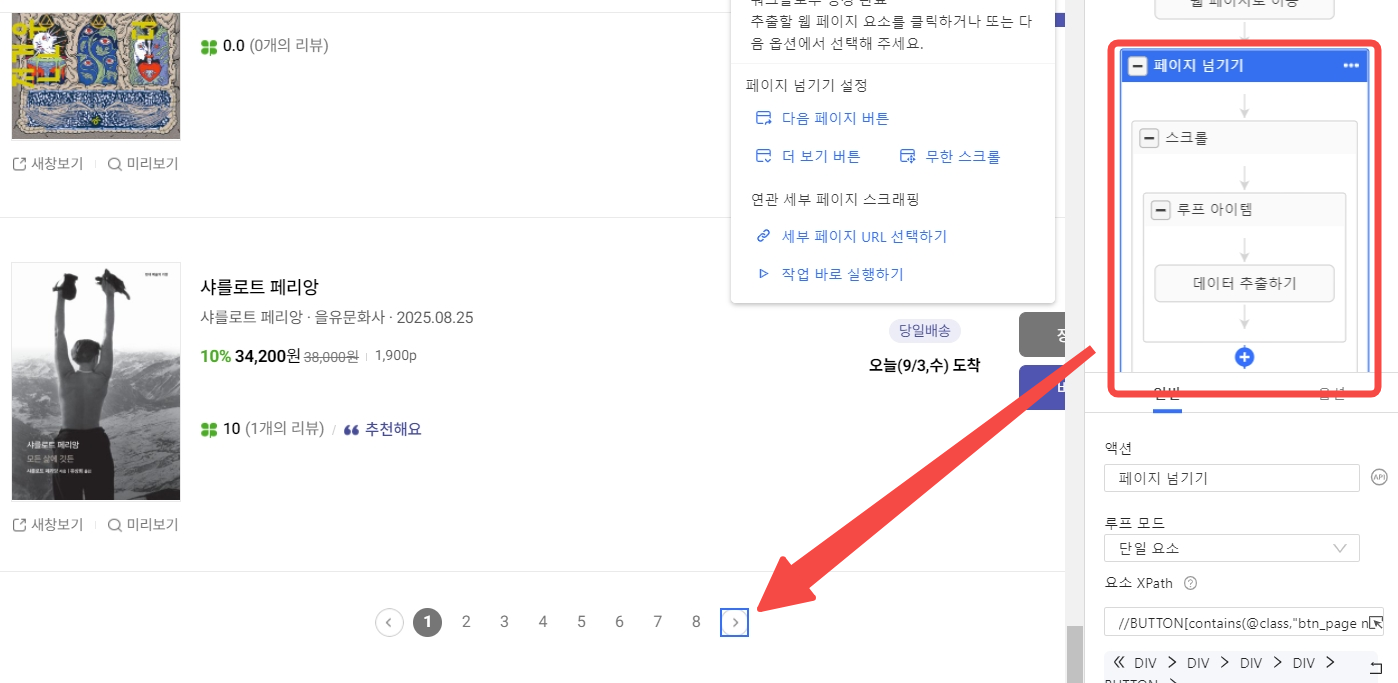
Step4: 추출할 데이터 필드 설정 및 데이터 추출 작업 실행
하방의 데이터 미리보기 패널에서 간단한 데이터 처리를 해줍니다.
데이터 필드 삭제, 추가는 물론 일부 데이터 필드에 대해 간단한 편집 작업(엑셀과 비슷)도 진행할 수 있습니다.
중복 데이터가 많은 경우 중복 제거 기능을 사용하여 처음부터 중복되지 않은 데이터만 엑셀 또는 데이터베이스로 내보낼 수 있어 후기 데이터 정제 작업량을 효과적으로 줄일 수 있습니다.
새창보기, 미리보기와 같은 데이터 분석에 쓸모없는 데이터는 데이터 필드 오른쪽의 더보기 버튼을 클릭 후 필드 삭제하기를 클릭하여 데이터 필드를 빠르게 삭제해 줍니다.
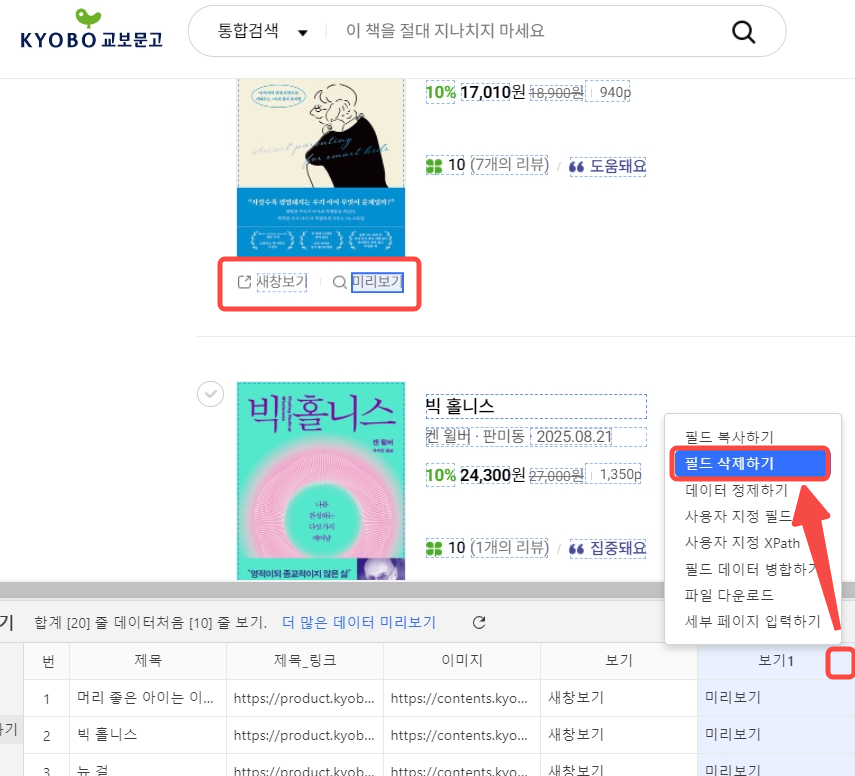
데이터 필드 이름도 굳이 파일 저장 후 엑셀에서 번거롭게 고칠 필요 없이 직접 더블 클릭하여 수정할 수 있습니다.
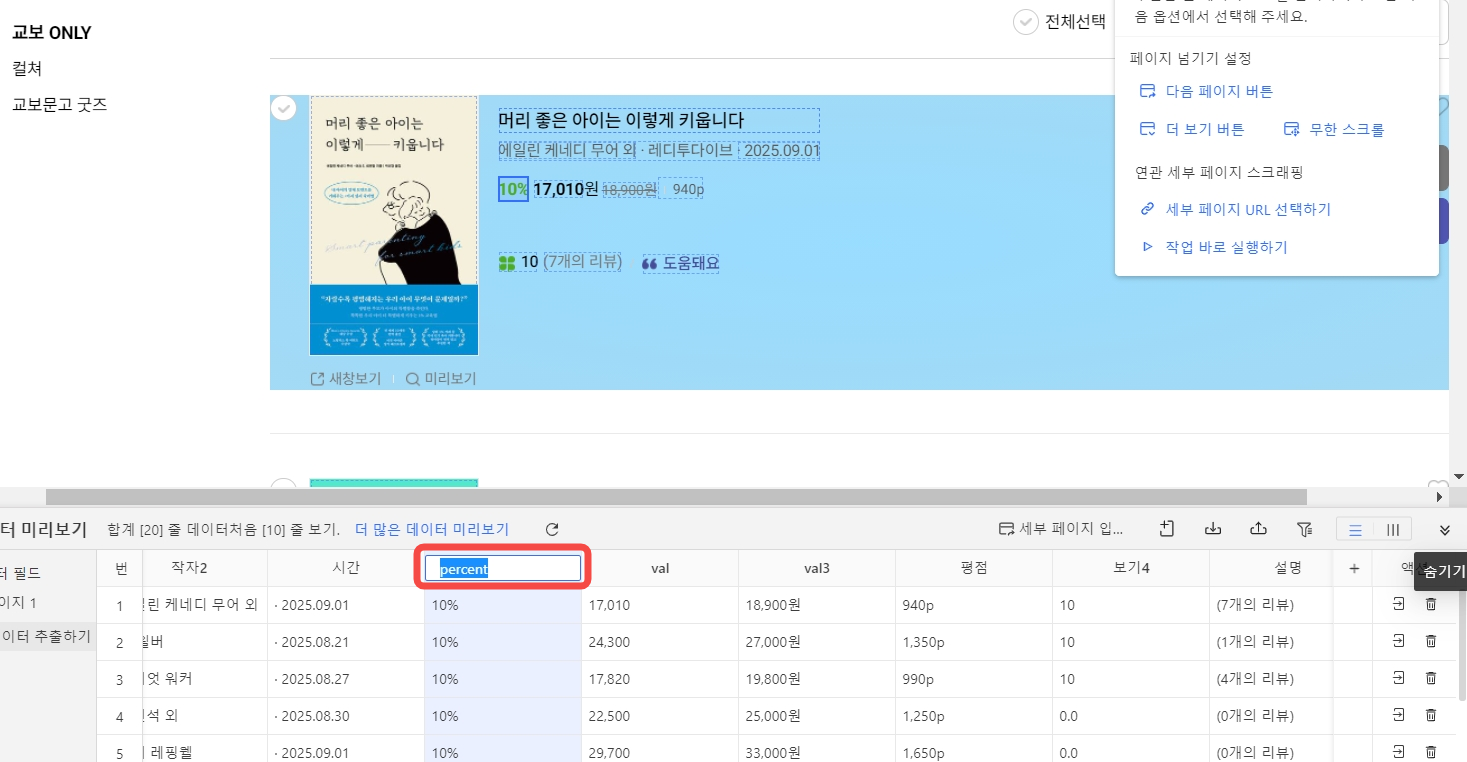
숫자와 관련된 데이터는 나중에 데이터 분석할 때 단위가 붙으면 공식을 사용할 때 번거롭잖아요. octoparse에서는 데이터를 내보내기 전에 데이터 필드 오른쪽의 더보기 – 데이터 정제하기를 통하여 데이터 전처리까지 진행할 수 있습니다.
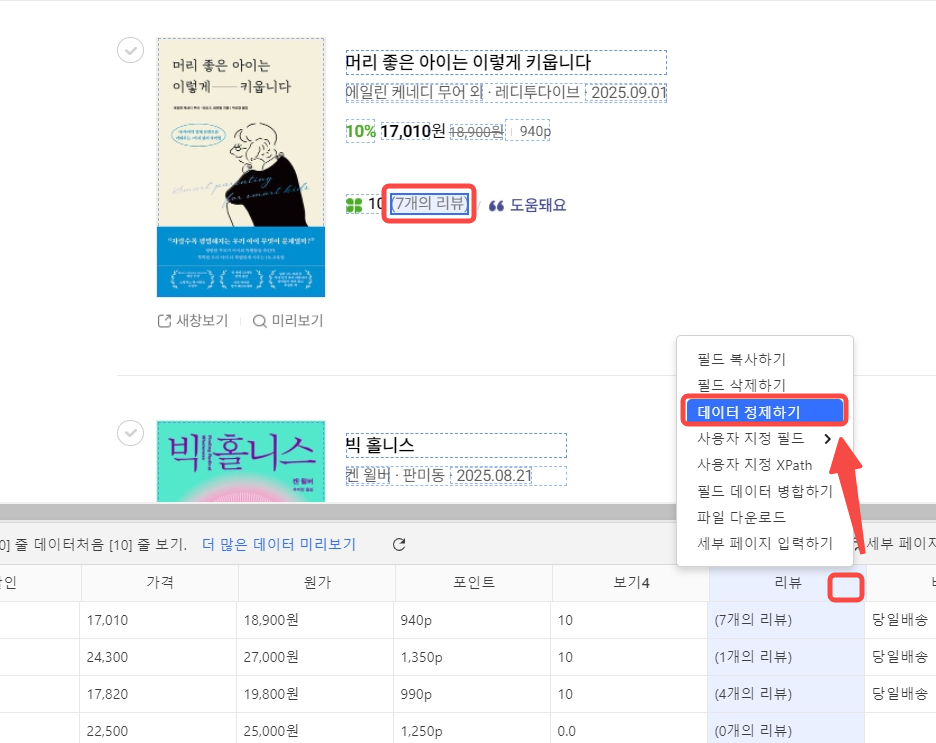
데이터 정제하기 클릭 후 보조 추가하기- 정규표현식으로 매치하기를 클릭합니다.
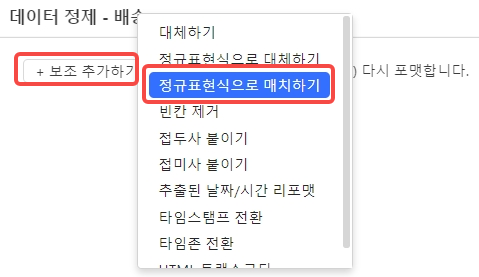
정규 표현식 도구에서 규칙 생성을 선택 후 다음과 같이 설정 후 생성 버튼을 클릭하고 스크롤하면
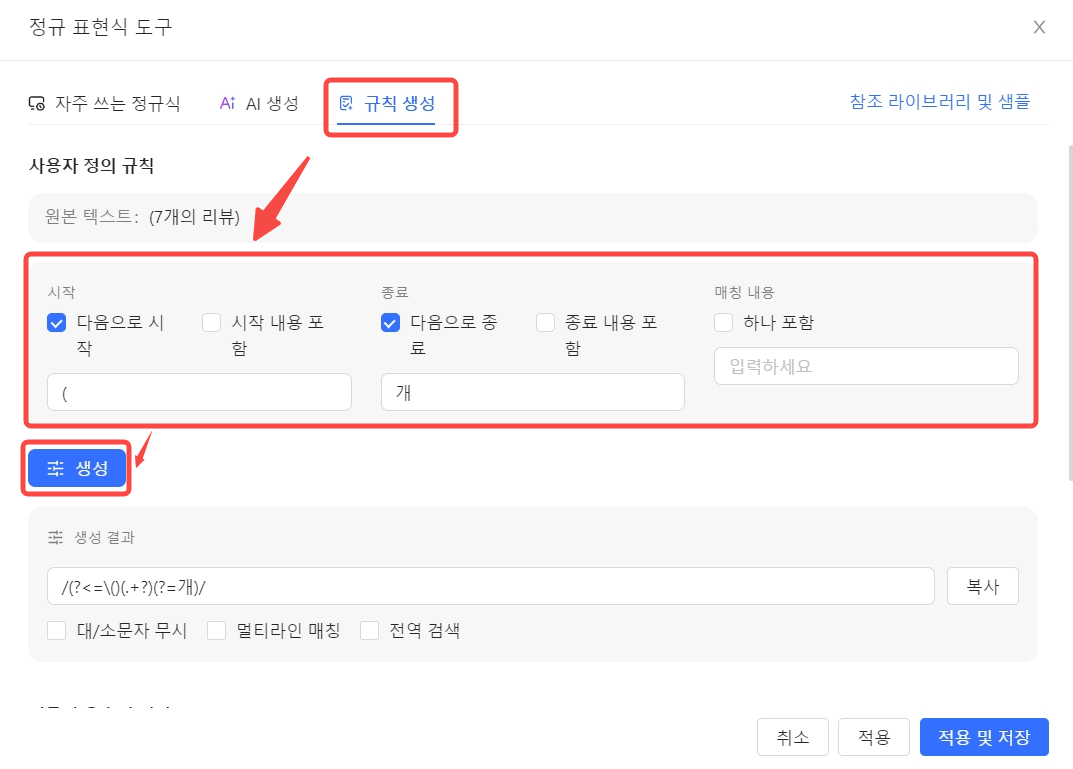
아래 부분에서 정규식 유효성 검사에서 몇 개 데이터의 처리 상태를 확인할 수 있습니다.
예상과 다르다면 여러 번 규칙을 변경해 주시고, 예상과 부합한다면 사용 및 저장 버튼을 클릭하면 됩니다.

정규표현식으로 매치하기로 돌아와서 테스트 버튼을 클릭하면 설정한 정규식이 잘 적용된 것을 확인할 수 있습니다.
확인 버튼을 클릭해 줍니다.
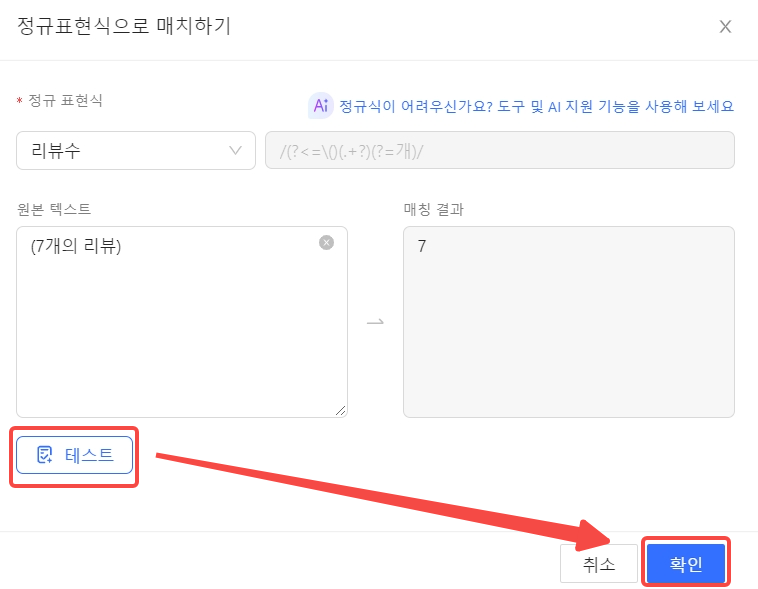
설정 후 적용 버튼을 클릭해 줍니다.

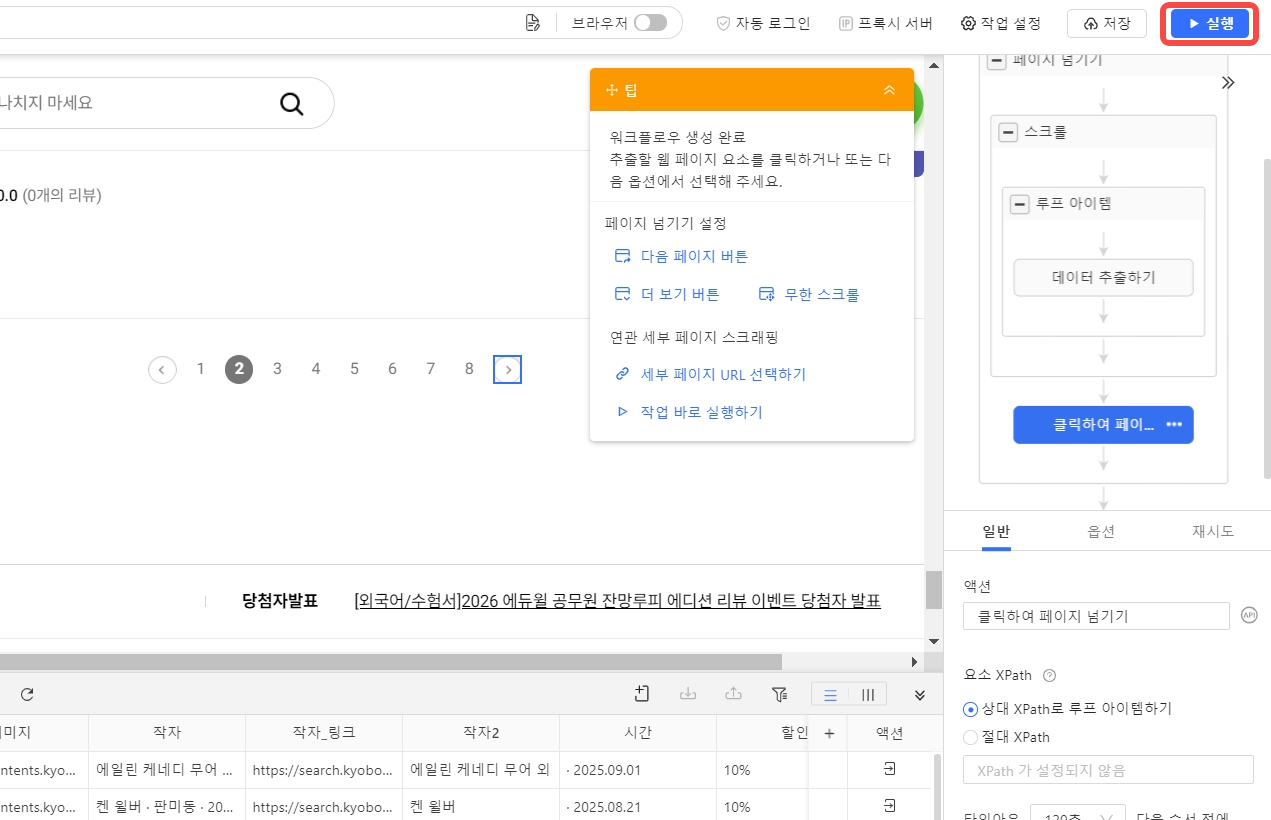
여러 페이지로 구성된 도서 정보를 추출해야 하기에 페이지 넘기기가 정상적으로 작동하는지 체크해 보아야 합니다. 페이지 넘기기 클릭 후 클릭하여 페이지 넘기기를 클릭하면 왼쪽 내장 브라우저에서 페이지가 제대로 넘겨지고 있는지 확인할 수 있습니다.
*일부 웹 사이트는 >버튼을 클릭하면 10페이지씩 넘겨지는 경우가 있어요. 이런 경우에는 현재 페이지 기준으로 다음 페이지를 클릭할 수 있도록 xpath를 설정해 주셔야 됩니다.
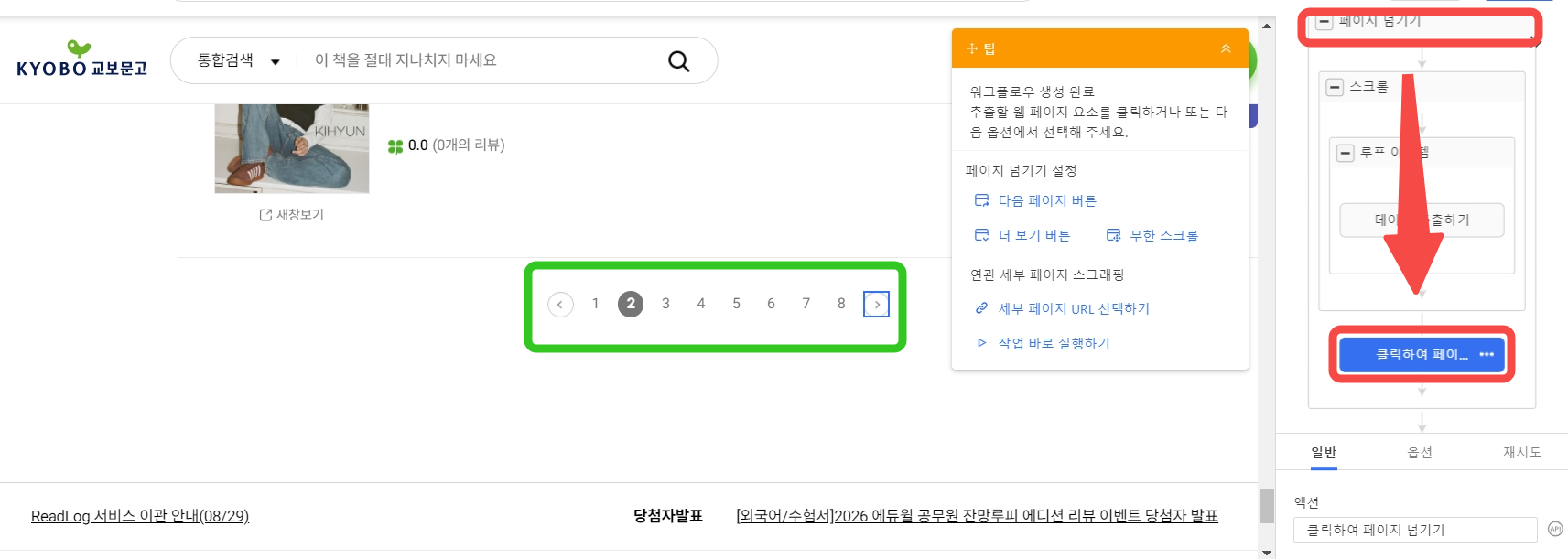
작업 설정에 문제가 없으면 우측 상단의 실행 버튼을 클릭하여 데이터 추출 작업을 시작해 줍니다.
원하는 실행 모드을 선택해 주시면 됩니다.

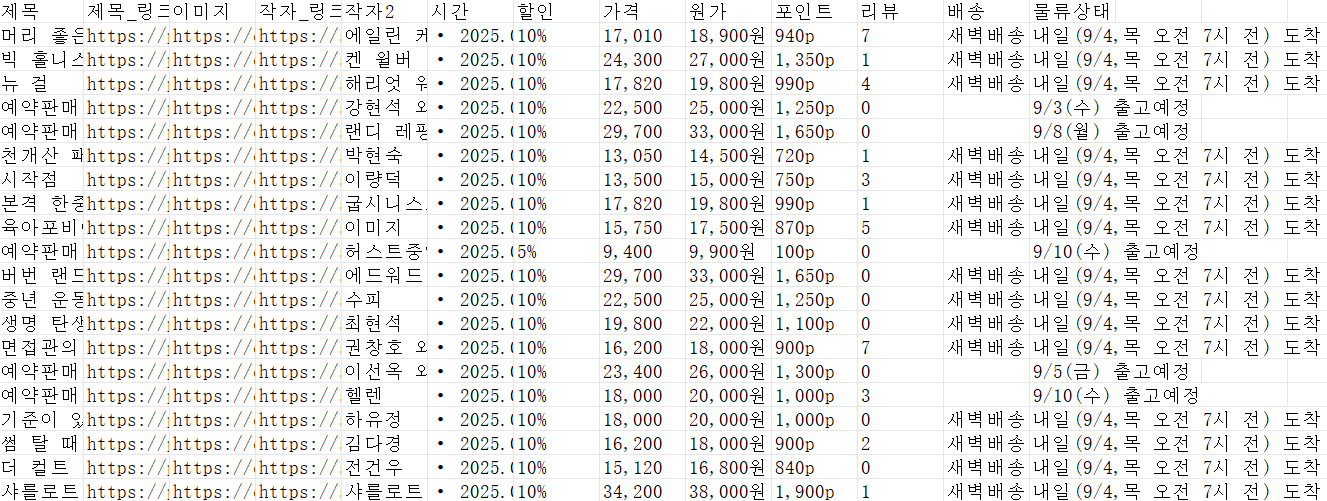
작업 실행 완료 후 데이터 내보내기 방식을 선택할 수 있어요. 엑셀, 구글 시트, 데이터베이스 등 여러 방식으로 내보낼 수 있지만 저는 가장 많이 사용되는 엑셀로 내보냈습니다.
마무리
지금까지 옥토파스를 이용해 교보문고 웹사이트의 도서 정보를 추출하는 방법을 알아보았습니다. 복잡한 코딩이나 프로그래밍 지식 없이도, 단 몇 분 만에 원하는 데이터를 확보할 수 있다는 것을 확인하셨을 겁니다.
옥토파스는 데이터 수집의 불편함을 해소하고, 여러분이 더 가치 있는 분석과 전략 수립에 집중할 수 있도록 돕는 강력한 도구입니다. 이번 포스팅에서 소개한 교보문고 외에도 다양한 웹사이트의 데이터를 손쉽게 추출할 수 있으니, 여러분의 데이터 활용 역량을 한 단계 더 업그레이드해보세요!
이 글이 여러분의 데이터 수집에 큰 도움이 되기를 바랍니다. 궁금한 점이 있다면 언제든지 댓글로 문의해 주세요. 다음 포스팅에서는 추출한 도서 데이터를 활용하는 다양한 방법에 대해 소개해 드리겠습니다.
감사합니다!



