웹 스크래핑은 스크래핑 봇과 같은 컴퓨터 프로그램을 사용하여 여러 웹사이트에서 웹 데이터를 추출하는 기술입니다. 특정 웹사이트에서 비교적 많은 양의 정보를 주기적으로 또는 대량으로 얻어야 하는 작업에 특화된 맞춤 솔루션이 바로 웹 스크래핑이며 데이터 수집 임무를 완수하는 데 걸리는 시간과 노력을 대폭 줄일 수 있습니다. 이 블로그에서는 여러 URL 목록에서 데이터를 쉽게 스크래핑하는 방법을 알아볼 수 있습니다 .
코딩 없이 URL 목록을 스크래핑하는 방법
코딩에 능숙하지 않거나 프로그래밍 경험이 부족더라도 코드가 필요 없는 웹 스크래핑 도구를 사용하여 쉽게 웹 스크래핑을 수행할 수 있습니다.
Octoparse는 다양한 데이터 유형의 데이터 추출을 위해 설계된 웹 스크래퍼입니다. URL, 전화번호, 이메일 주소, 제품 가격 및 리뷰는 물론 메타 태그 정보 및 본문 텍스트를 스크래핑할 수 있습니다. 온라인 스크래핑 템플릿을 사용하거나 소프트웨어를 다운로드하여 매뉴얼 모드를 사용하여 여러 URL에서 데이터를 추출하는 두 가지 방법을 제공합니다.
온라인 사전 설정 템플릿을 사용하여 URL 목록 스크래핑하기
Octoparse는 Amazon, eBay, Google Maps, LinkedIn 등과 같은 인기 있는 사이트에 대한 사전 설정된 데이터 스크래핑 템플릿을 제공합니다. 이러한 템플릿을 사용하면 키워드를 검색하거나 여러 URL을 일괄적으로 입력하여 쉽게 데이터를 얻을 수 있습니다. Octoparse 템플릿 페이지에서 데이터 템플릿을 찾고 데이터 샘플을 미리 볼 수 있습니다. 아래 링크에서 Google Maps Listing Scraper를 시도하고 구글 지도의 목록 페이지에서 이름, 주소, 태그, 전화번호, 지리적 정보 등의 데이터를 추출합니다.
https://www.octoparse.com/template/google-maps-scraper-listing-page-by-url
Octoparse로 URL 리스트 스크래퍼 사용자 정의하기
Octoparse 매뉴얼 모드는 사용자 지정 데이터 요구 사항을 처리하는 데 더 많은 유연성을 제공합니다. 템플릿에서 다루지 않은 웹사이트에서 데이터를 가져오거나 필요한 데이터를 템플릿을 사용하여 정확히 스크래핑할 수 없는 크롤러를 처음부터 제작할 수 있습니다.
하지만 Octoparse의 자동 인식 모드를 사용하면 코딩 기술 없이도 여러 URL 스크래퍼를 쉽게 제작할 수 있습니다. Octoparse를 다운로드하고 아래의 간단한 단계를 따르거나 Octoparse에서 URL 일괄 입력에 대한 튜토리얼을 읽고 자세한 내용을 알아보세요.
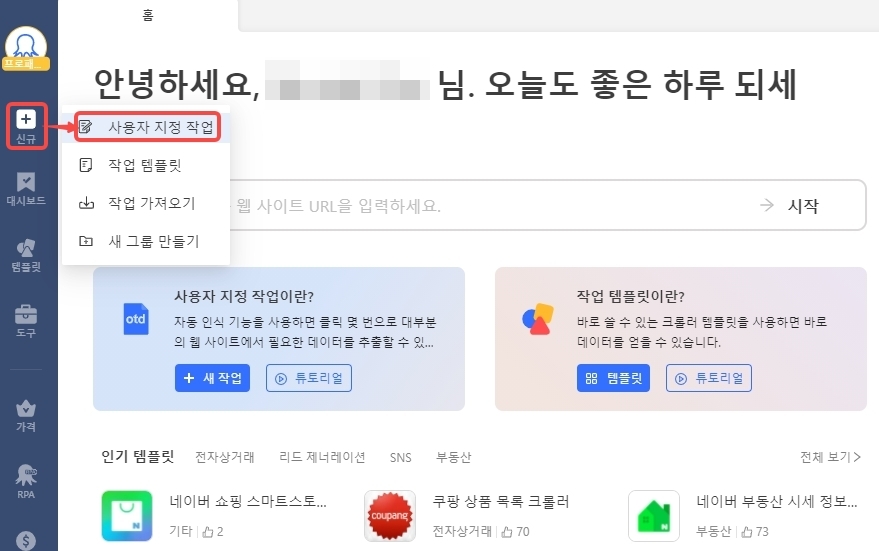
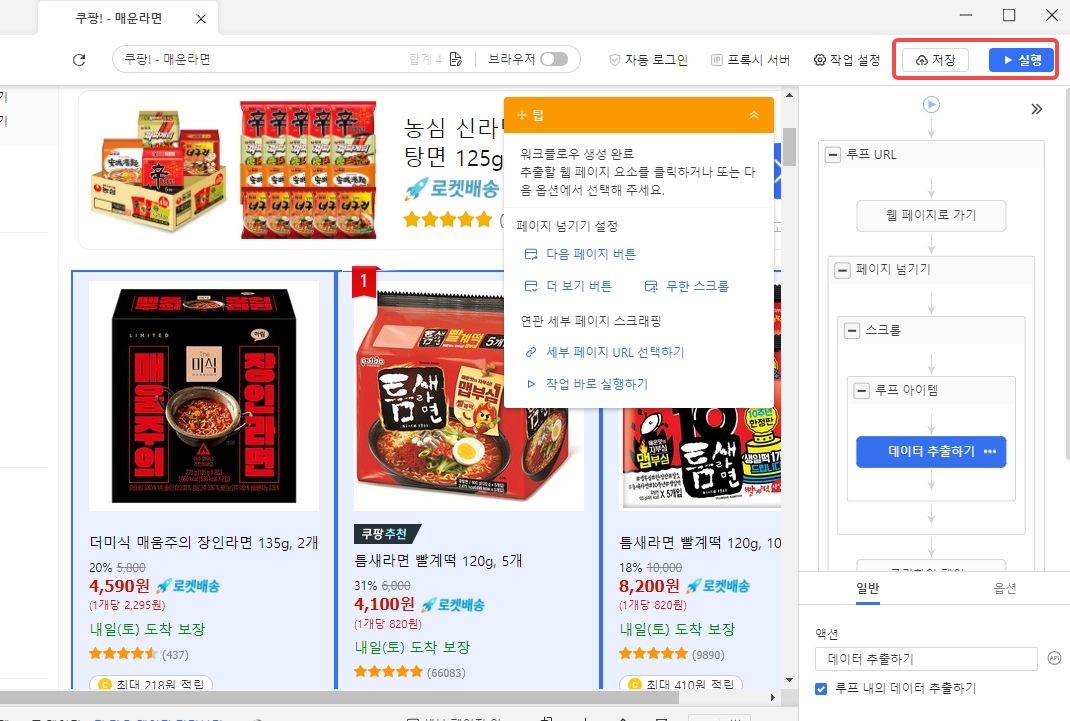
1단계: 사이드바에서 “+신규” 버튼을 클릭하고 “사용자 지정 작업”을 선택하여 새 작업을 만듭니다.
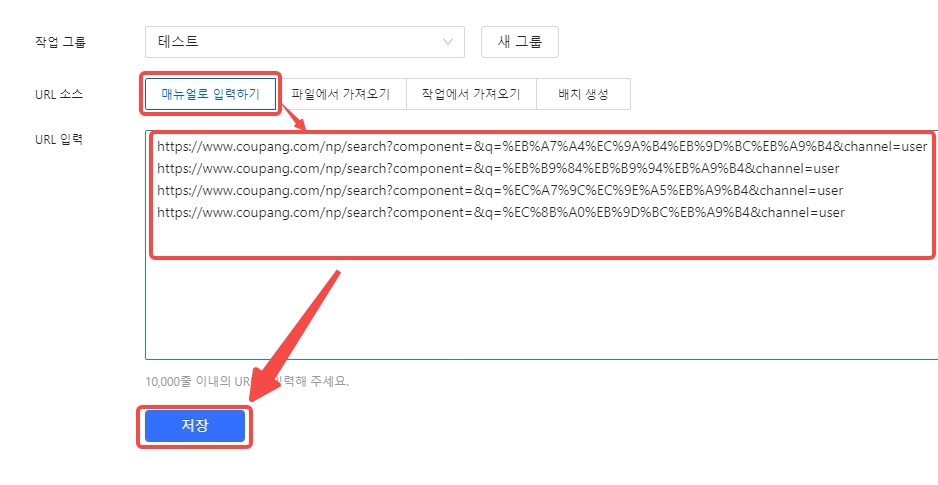
2단계: URL 목록을 복사하여 텍스트 입력창에 붙여넣고 “저장”을 클릭합니다. Octoparse가 자동으로 워크플로우를 생성합니다.
3단계: 자동 인식 기능을 사용하여 페이지 로딩이 완료되면 스크래핑 프로세스를 시작합니다. 스크래퍼는 자동으로 데이터를 식별하고 어떤 데이터를 스크래핑하고 싶은지 “추측”합니다.
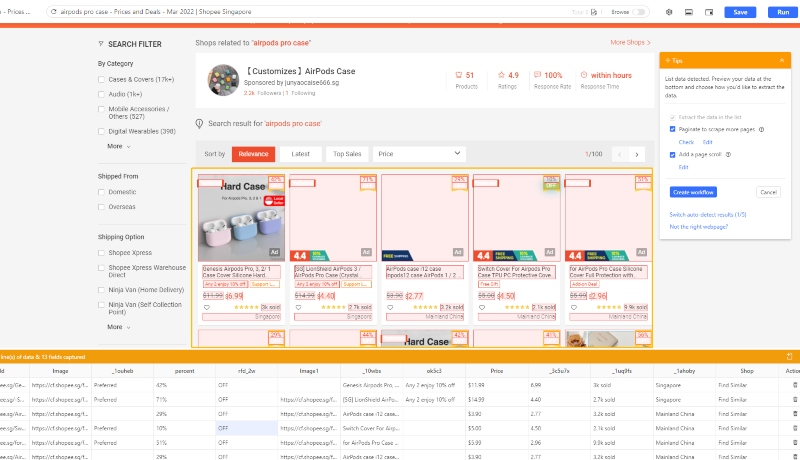
“추측”이 100% 정확하지 않더라도 걱정하지 마세요. 다른 데이터 세트로 전환하거나 웹 데이터를 수동으로 클릭하여 스크래핑할 데이터 필드를 추가할 수 있습니다.
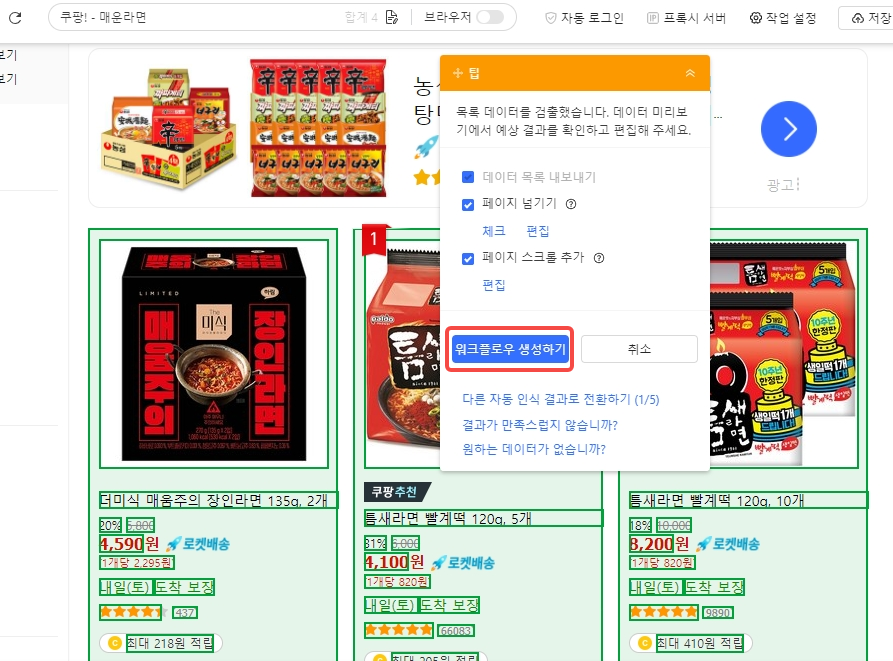
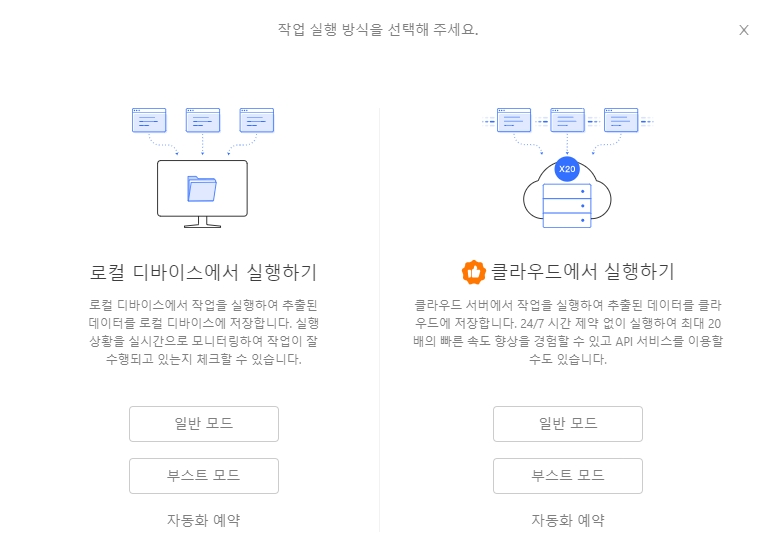
4단계: 작업 설정을 완료한 후 “저장”을 클릭하고 작업을 실행하여 데이터를 가져오세요! 로컬 또는 클라우드에서 작업을 실행하도록 선택할 수 있습니다.
Python으로 웹사이트의 모든 URL 가져오기
우수한 프로그래밍 지식과 기술적 배경이 있다면 Python에서 제공되는 Beautiful Soup, Scrapy, Selenium과 같은 패키지를 활용하여 URL 스크래퍼를 직접 제작할 수 있습니다. 다시 말해, 프로그래밍 언어에 능숙하다면 코드를 작성하여 직접 크롤러를 만들 수 있습니다. 직접 코드를 작성하면 유연하게 복잡한 상황을 처리할 수 있습니다.
Python을 사용하여 여러 URL에서 데이터를 스크래핑하는 단계
Python을 사용하여 여러 URL에서 데이터를 스크래핑하려면 HTTP 요청을 하거나 HTML 콘텐츠를 구문 분석하는 Beautiful Soup것과 같은 라이브러리를 활용할 수 있습니다. 다음은 Python에서 여러 URL에서 데이터를 스크래핑하는 방법을 보여주는 간단한 예입니다.
이 스크립트에서는:
- 해당
requests라이브러리는 URL로 HTTP 요청을 보내는 데 사용됩니다. - 해당
BeautifulSoup라이브러리는 웹페이지의 HTML 콘텐츠를 구문 분석하는 데 사용됩니다. - 스크립트는 URL 목록을 반복하며, 각 URL에 GET 요청을 보낸 다음, 웹 페이지의 제목을 추출하여 프린트합니다.
다음을 실행하여 필요한 라이브러리를 설치하세요.
보다 복잡한 스크래핑 작업의 경우 스크립트를 사용자 정의하여 특정 데이터 요소를 추출하고, 다양한 유형의 콘텐츠(예: JSON 또는 XML)를 처리하고, 오류를 관리하고, 스크래핑된 데이터를 CSV 또는 JSON과 같은 구조화된 형식으로 저장할 수 있습니다.
마무리
위에 언급된 방법을 사용하면 이제 여러 웹사이트 URL에서 데이터를 스크래핑하는 방법에 대한 도움이 될겁니다. 어느 정도 코딩 기초가 있다면 Python을 추천드리고, 코딩에 대해 전혀 모르거나 코딩을 배울 시간과 노력을 절약하고 싶다면 Octoparse를 추천드립니다.



